Preface
最好先读懂Transformer再来看这个实现,这次我没有具体讲每一行代码,主要是记录这次实现
代码链接:https://github.com/sukiAme7/G2P/tree/main
项目介绍
G2P介绍
Grapheme-to-Phoneme(G2P)转换是自然语言处理和语音处理中的基础任务,其目标是:
将一个词的拼写(字母/字素)序列转换为其发音(音素)序列。
比如下面的例子:
| 输入(字母序列) | 输出(音素序列) |
|---|---|
cat |
/k/ /æ/ /t/ |
physics |
/f/ /ɪ/ /z/ /ɪ/ /k/ /s/ |
G2P一些应用:
- 文本转语音(TTS)
- 将输入的文字转换成准确的发音(音素序列),供声学模型合成语音。
📌 例如:
1 | 输入:knowledge |
- 语音识别(ASR)中的词典构建
- 用于构建 发音词典(Lexicon),将语音信号与文字对应起来。
- 对于未登录词(OOV),G2P 可以自动生成其发音,补全词典。
📌 例如:
1 | ASR 模型需要将音频中的 /s/ /t/ /uː/ /d/ /ə/ /n/ /t/ 匹配到 "student" |
- 语言学习/教学工具
- G2P 模型可用于语言学习软件,展示正确的词语发音。
数据集
cmudict介绍
cmudict,全称是 CMU Pronouncing Dictionary,是由卡内基梅隆大学发布的一套免费开源的英文发音词典,广泛应用于语音合成(TTS)、语音识别(ASR)、G2P 模型训练等任务。它的核心作用是为每个英文单词提供标准的音素发音,用于将拼写(字母序列)映射为发音(音素序列)。
数据格式如下:
1 | HELLO HH AH0 L OW1 # 首先是单词 然后 是它的 发音音素 |
对于多音词,词典会列出多个发音,用 (1), (2) 等编号区分,比如:
1 | READ R EH1 D |
整个词典包含约 13 万个单词,覆盖了大多数常见和部分专业词汇,本次项目我是选择用这个数据进行训练。
CMUdict数据链接:https://github.com/cmusphinx/cmudict
数据预处理
在上述链接下载一个名为cmudict.dict的文件,该文件即为我们所要用的数据。然后打开这个文件观察一下数据的样式,可以发现每一行数据是一个单词 和它对应的发音:
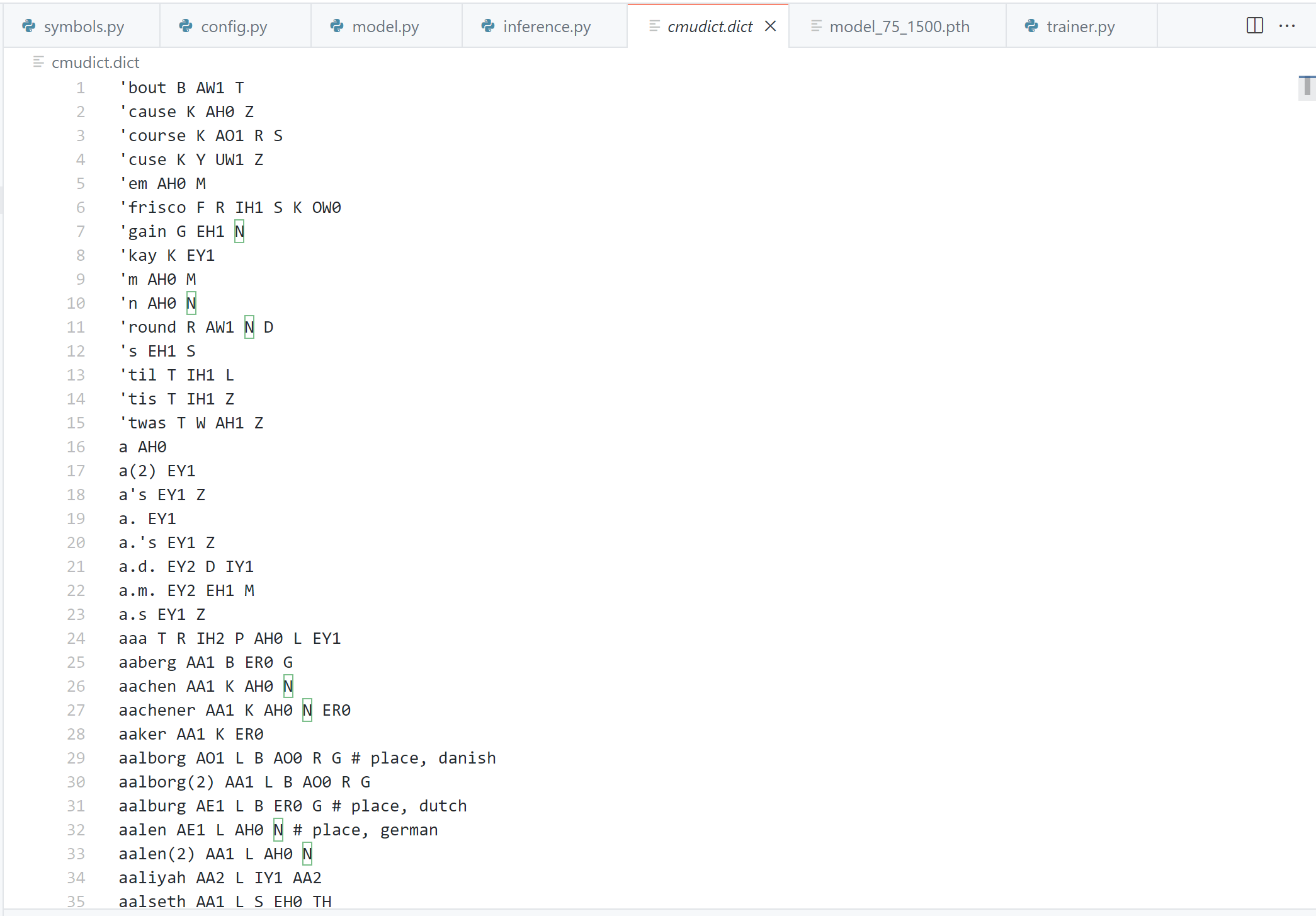
比如:
1 | abnormal AE0 B N AO1 R M AH0 L |
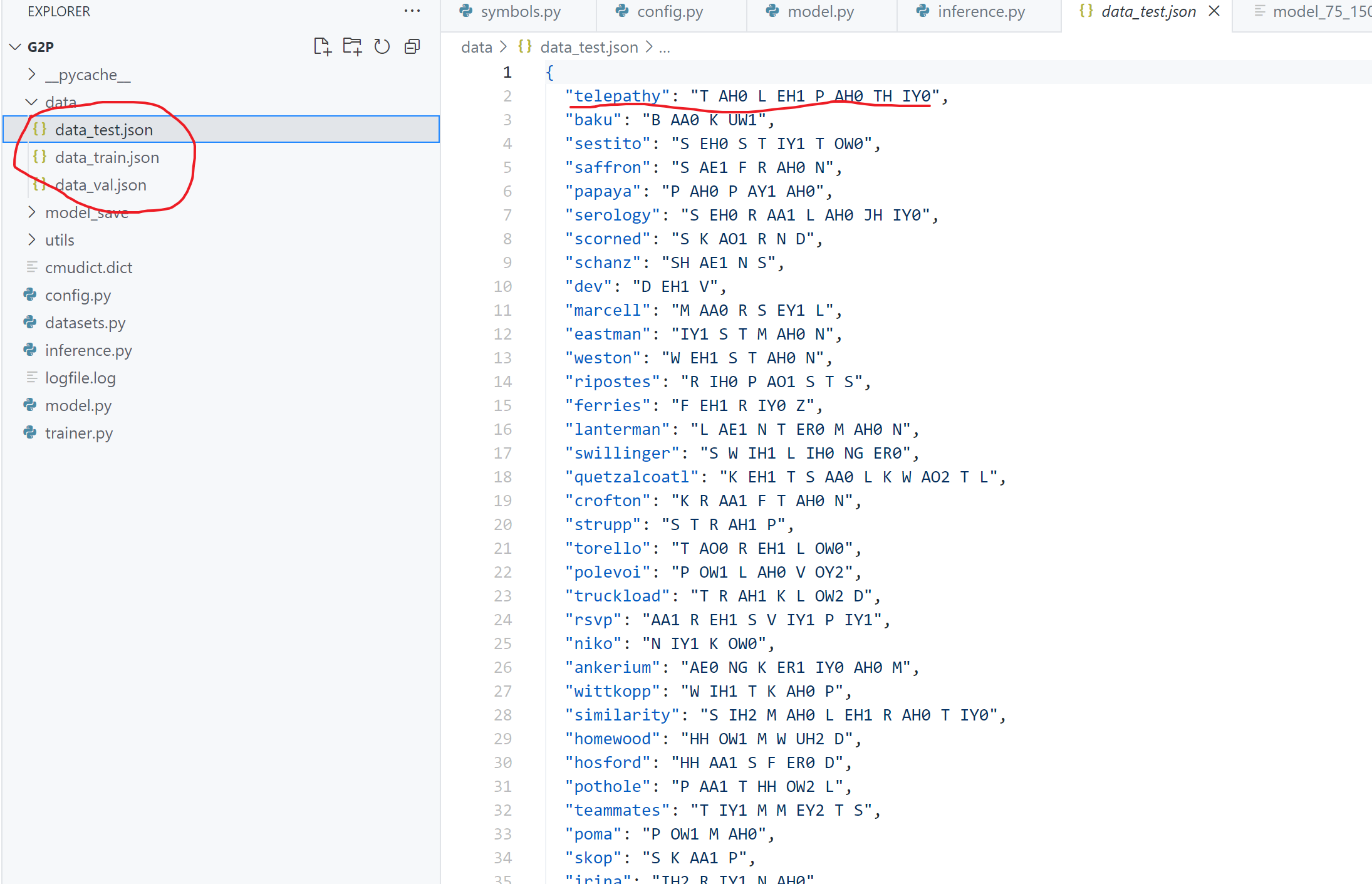
接着对数据进行预处理,将数据集按7:2:1进行划分,划分后得到三个json文件(如下图所示),同时我们预处理后的数据样式也如图中红线所示,一个单词对应一个发音音素。
数据预处理代码如下:
1 | ''' |
Transformer
建议先看看上一篇文章明白Transformer的原理以及每个模块干嘛,否则会不理解代码实现
本次G2P项目属于NLP领域,因此我打算选用Transformer作为本次项目的模型。接下来开始对Transformer的代码进行具体实现。
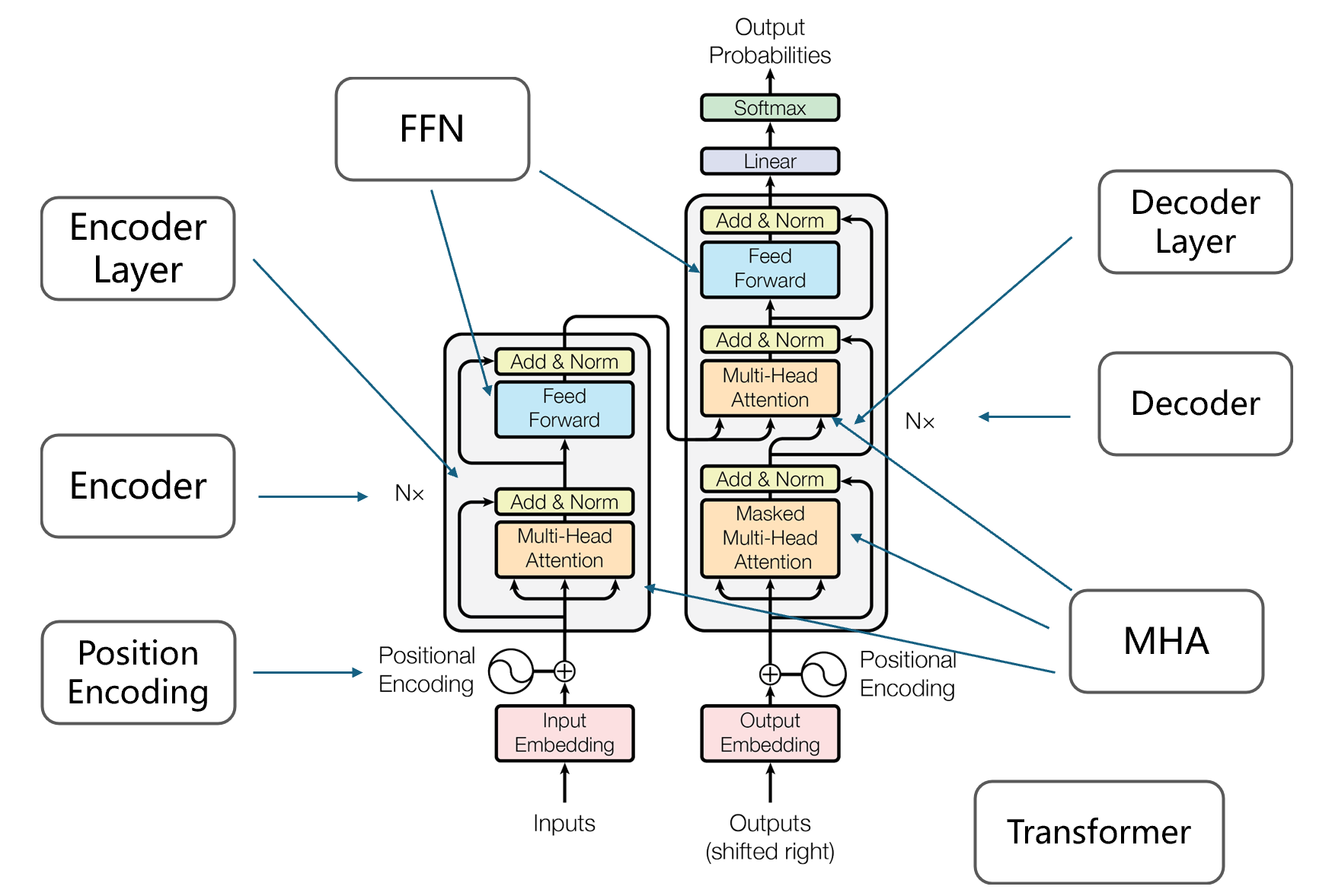
对于模型的实现,我们首先会分为8个类,如上图所示:
- Transformer类是对最后整体进行封装
- MHA是多头注意力类
- FFN是前向反馈网络类
- Positional Encoding是位置编码类
- Encoder是指N个Encoder Layer的堆叠,同理Decoder是对多个Decoder Layer的堆叠
Positional Encoding
为了使模型能够利用序列中的顺序信息,还需要注入一些关于tokens在序列中相对或绝对位置的信息。为此,论文在编码器和解码器堆栈底部的输入嵌入中加入了位置编码。位置编码的维度与嵌入向量相同即 $d_{model}$,因此它们可以直接相加。
论文用到的位置编码公式:
$$
PE(pos,2i)=sin(pos/10000^{2i/d_{model}})\
PE(pos,2i+1)=cos(pos/1000^{2i/d_{model}})
$$
具体代码实现如下:
1 | class PositionalEncoding(nn.Module): |
Multi Head Attention
接着多头注意力机制实现,首先我们将输入通过一个Linear层转化成 Q,K,V,接着将 每个Q,K,V分成8个头(论文中是8个,看具体情况自己定义),接着进行注意力计算,最终在进行拼接返回:
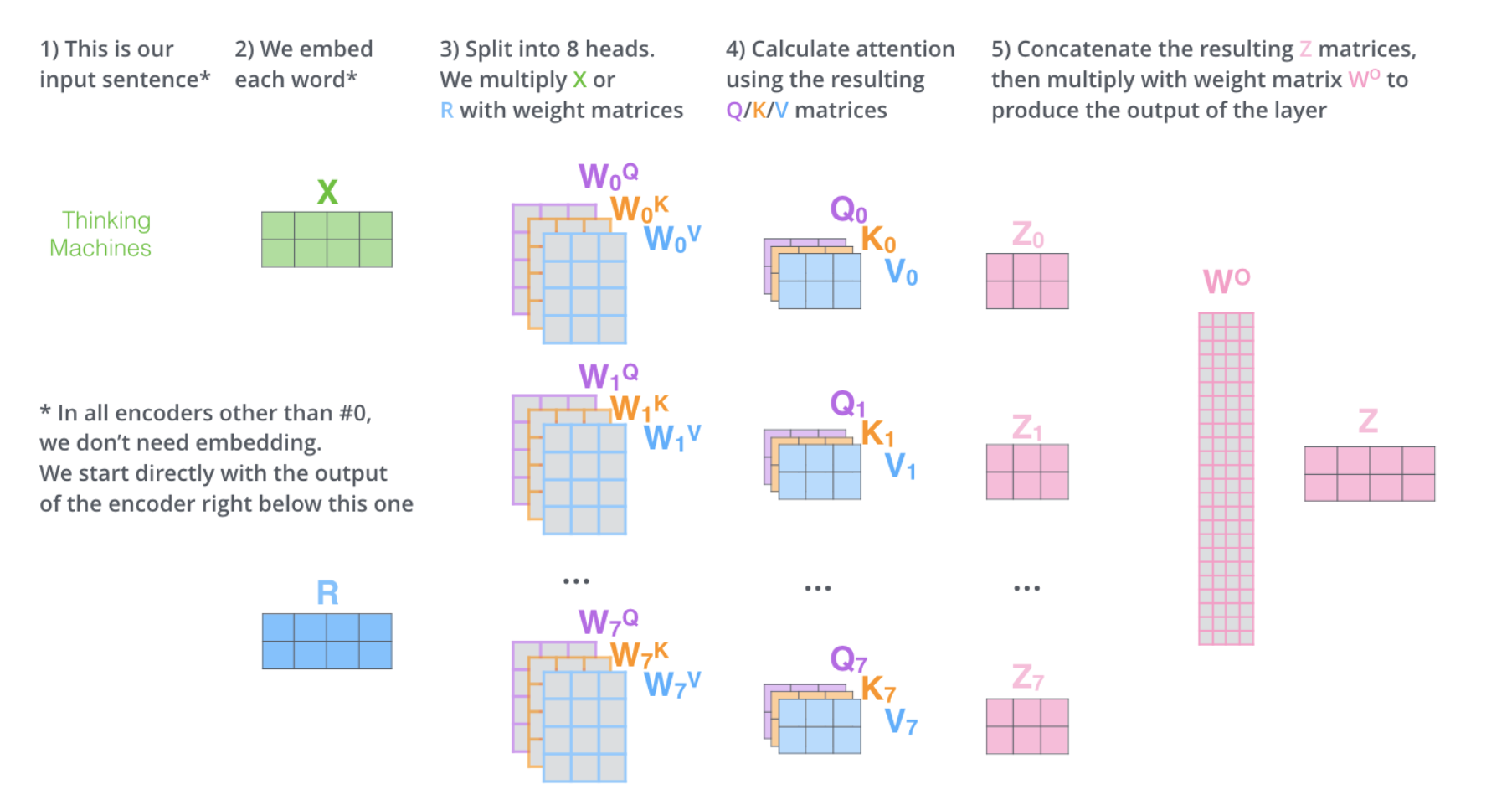
1 | class MultiHeadAttentionLayer(nn.Module): |
Feed Forward Layer
前向网络结构比较简单,两个线性层同时注意加上Dropout,因为线性层这里计算比较耗时。
1 | class PointWiseFeedForwardLayer(nn.Module): |
Encoder Layer
首先一个Encoder Layer的结构如下图所示:
- 多头自注意力
- FeedFowrd
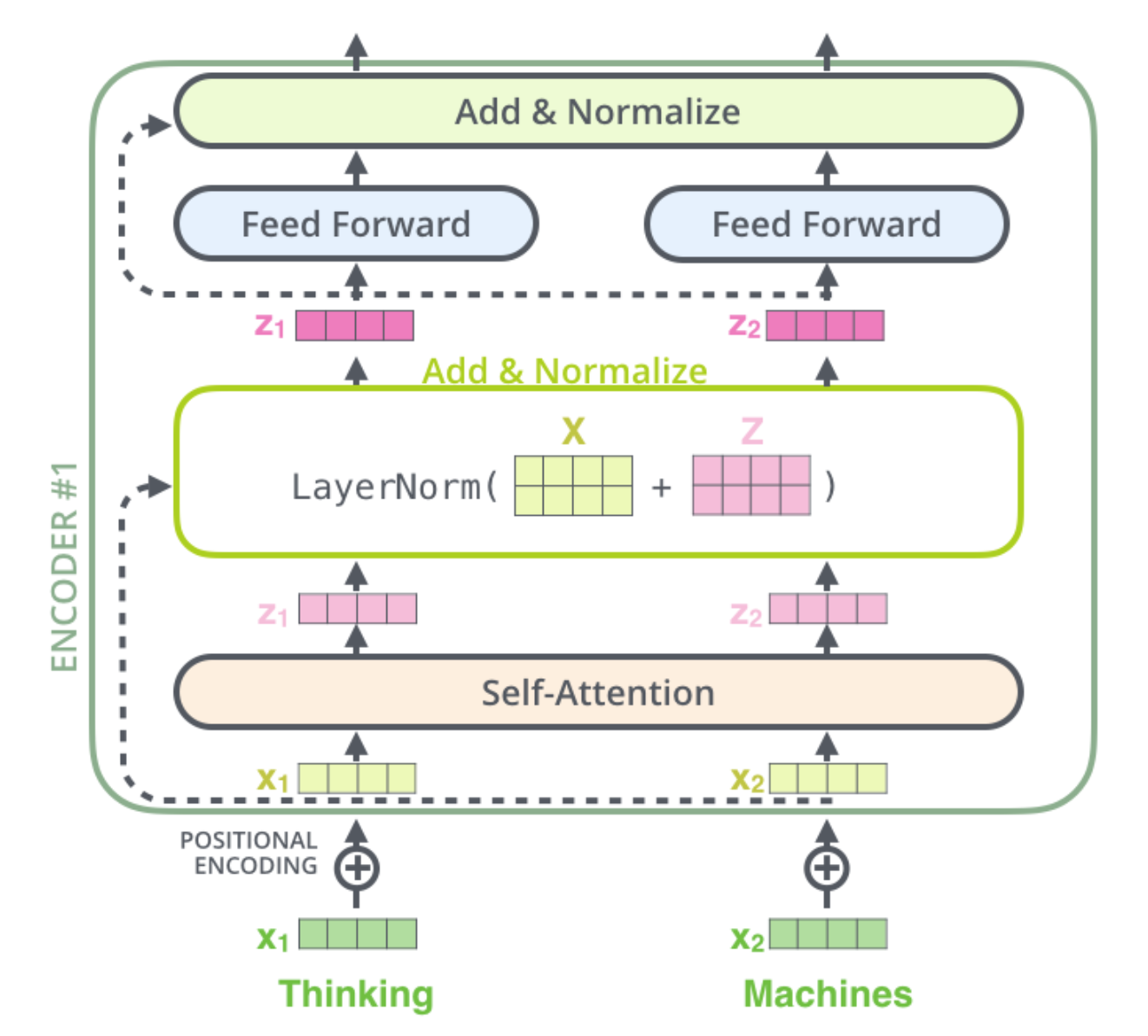
代码实现如下:
1 | class EncoderLayer(nn.Module): |
Encoder
编码器是多个Encoder Layer的堆叠,所以具体实现如下:
1 | class Encoder(nn.Module): |
Decoder Layer
每一层解码器包含:
- 多头自注意力
- Encoder-Decoder交叉注意力
- FFN
1 | class Decoder_layer(nn.Module): |
Decoder
同Encoder,Decoder是多个Decoder Layer的堆叠
1 | class Decoder(nn.Module): |
Transformer
对上述所有模块进行封装:
1 | class Transformer(nn.Module): |
训练
具体训练脚本如下:
1 | import os |
我在一张A800显卡上训练了50分钟,总共100个Epoch,batch size大小为4096.
推理
基于上述训练的模型进行推理:
1 | from model import Transformer |
推理示例:
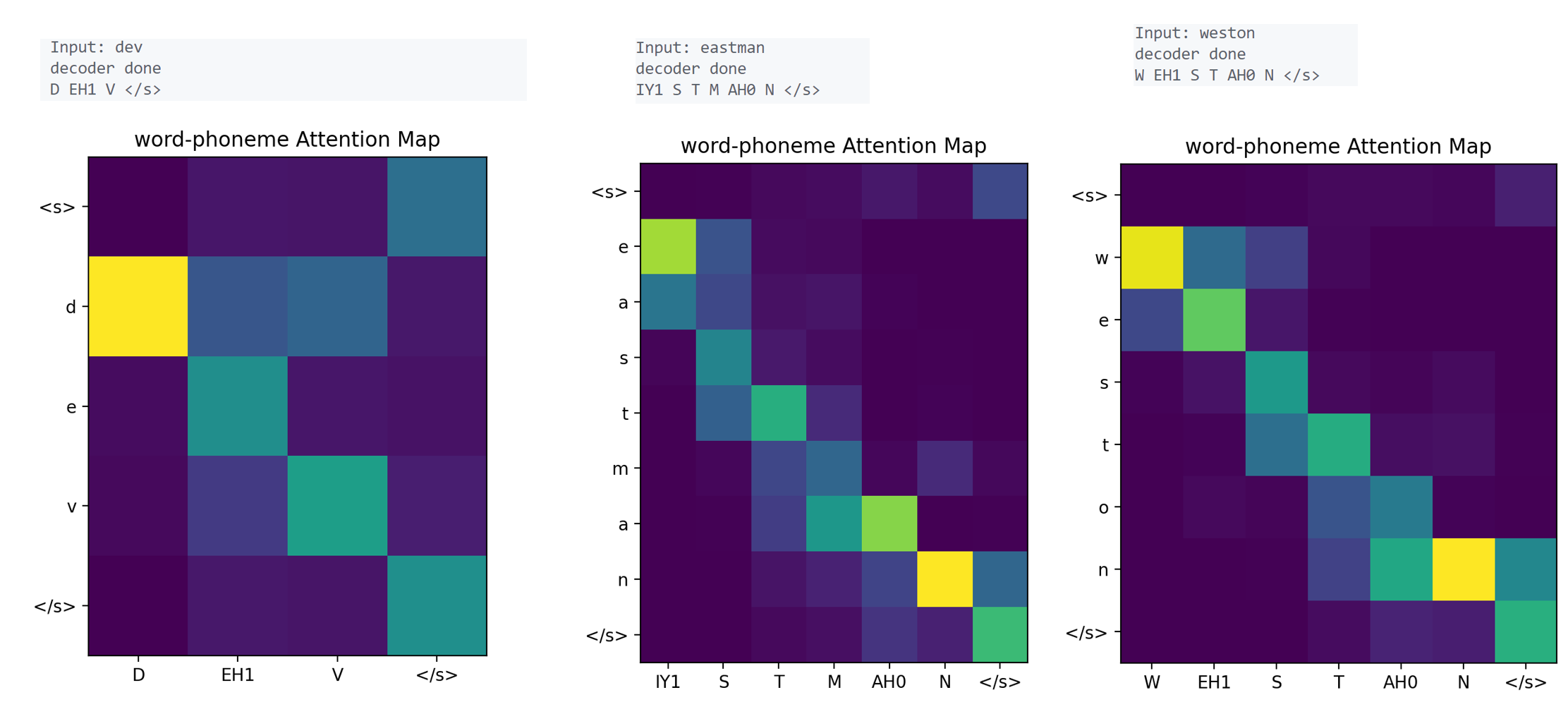
从测试集随便找三个单词如图,分别是“dev”,”eastman”,”weston”

然后执行推理脚本:
可以发现在测试集上全部解码正确,训练时并未用到测试集,说明模型训练的效果很不错。