
Support Vector Machine
什么是SVM?
SVM英文全程Support Vector Machine,使用SVM的思想既可以解决分类问题也可以解决回归问题。
先来看看SVM的思想:
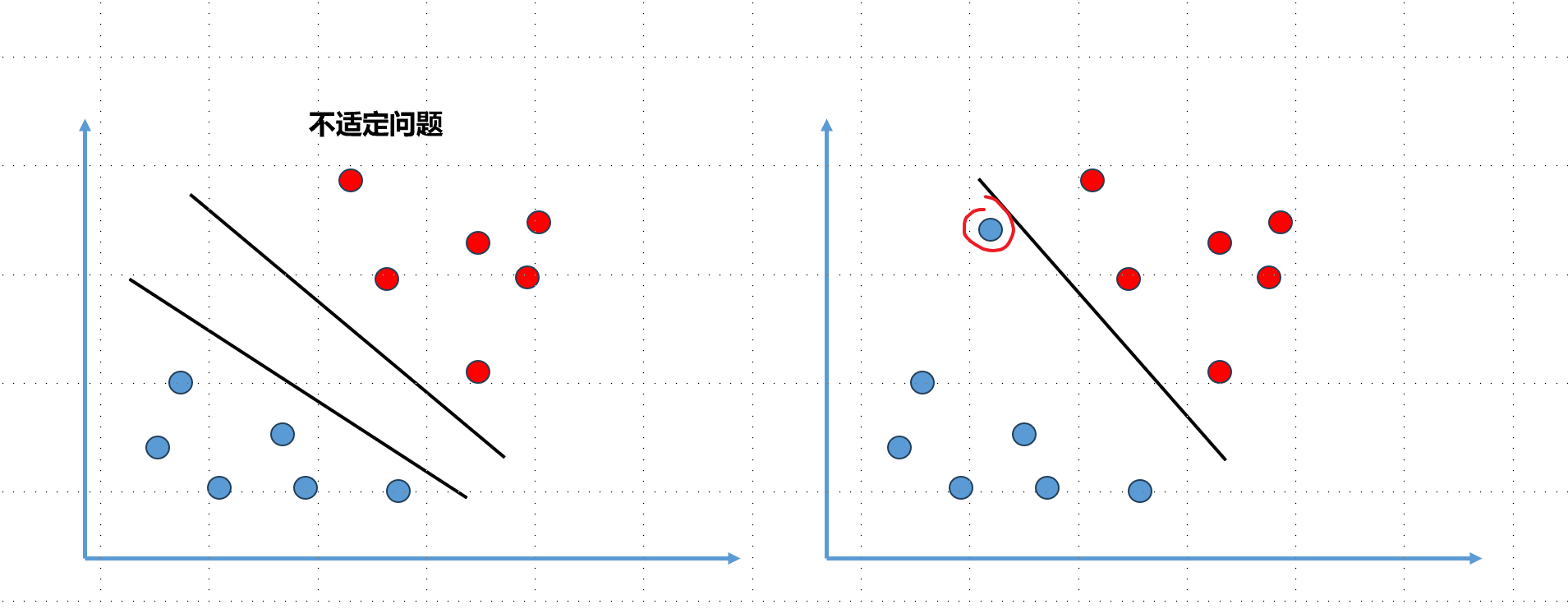
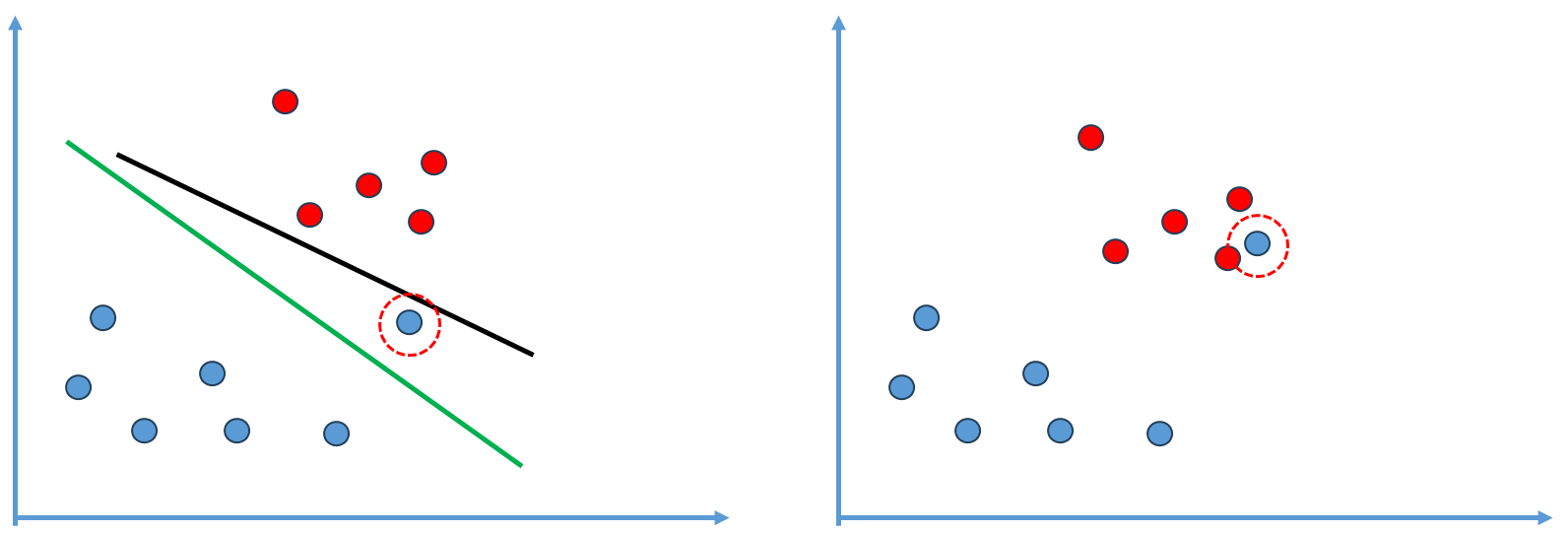
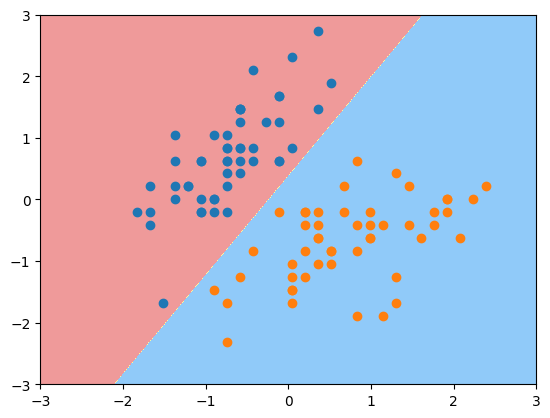
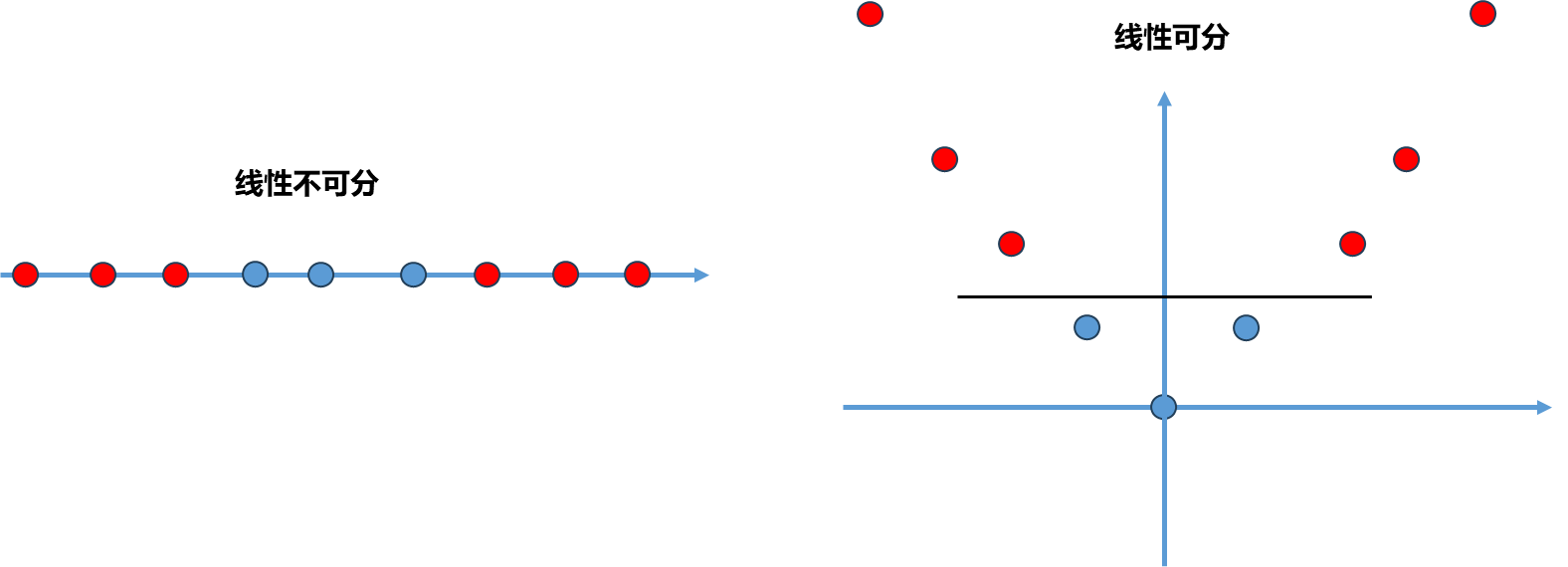
前面介绍的逻辑回归算法本质就是在特征平面中找到一个决策边界,数据在决策边界属于一类,在另一侧属于另外一类。不过对于很多数据而言存在决策边界并不唯一的问题(如上左图),也叫做不适定问题。
逻辑回归算法如何解决不适定问题的?其定义了一个概率函数$\sigma$ 函数,根据概率函数进行建模形成了一个损失函数,然后最小化这个损失函数从而求出一条决策边界,在这里损失函数是完全由训练数据集决定的。
SVM解决问题的方式稍微不同,假设决策平面如上面右图的直线,这根直线将训练数据非常好的划分成两部分,但是存在泛化能力的问题,假如新来一个样本点(红圈蓝点),根据此时的决策边界其被分类为蓝色,但实际上这个点分为红色类别更加合理,这个决策边界泛化效果不够好,因为这个决策边界离红色点太近了,导致其它离红色很近的点被误分在另外一侧。
那么什么样的边界泛化能力比较好呢?
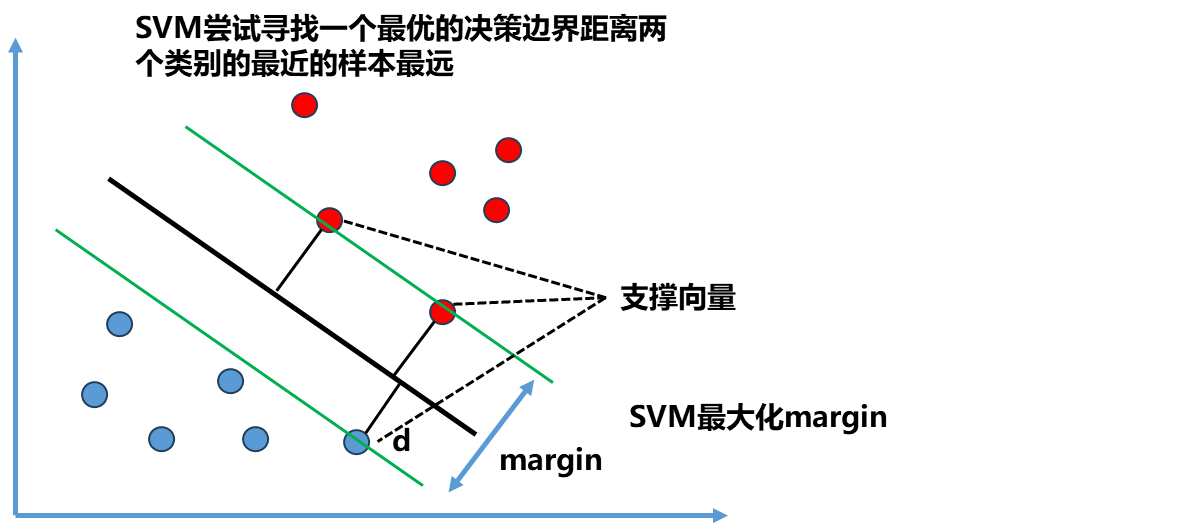
如图中黑色加粗的直线,离这根直线最近的点(图中一共由三个点),让这些点离黑线尽可能的远,即希望决策边界黑线离红色的点尽可能远,也离蓝色的点尽可能远,同时还能很好的分别两种类别的数据点。
总结来说,SVM尝试寻找一个最优的决策边界距离两个类别的最近的样本最远。这些最近的点如图中的两个红色点和一个蓝色点被称做支撑向量,这也是SVM名字的由来。这些支撑向量定义了一个区域,而最终最优的决策边界就是被这个区域所定义。确定区域的两根直线它们之间的距离通常叫做Margin=2d, SVM算法就是要最大化Margin.
决策边界不仅要很好的把训练数据进行很好的划分,同时考虑到未来,让其泛化能力尽可能好。
上面的例子解决的是线性可分的问题,即对于所有样本点来说存在一根直线或者高维空间中存在一个超平面可以将这些点完全分开,这样的算法也叫做Hard Margin SVM.但真实情况很多数据是线性不可分的,在这种情况下可以通过改进成Soft Margin SVM解决.
SVM背后的最优化问题
SVM算法本质就是最大化Margin,这个margin就是两个类相应的支撑向量之间的距离,那么这个Margin数学表达是怎么样的?从上面的图中可以看出$margin=2d$ ,那么即SVM要最大化$d$ ,所以找到$d$ 的表达式就可以求解这个问题.
高中解析几何中点到直线的距离公式:
$$
点(x,y)到直线Ax+By+C=0的距离\
\frac{|Ax+By+C|}{\sqrt{A^2+B^2}}
$$
拓展到n维空间:
$$
\theta^Tx_b=0-> w^Tx+b=0\
\frac{|w^Tx+b|}{||w||}\
||w||=\sqrt{w_1^2+w_2^2+…+w_n^2}
$$
假设决策边界为$w^Tx+b=0$ 的表达式, SVM算法期望的是对于两类样本数据点离我们最终的决策边界的那些点到决策边界距离为d,因此所有的点到决策边界的距离都应该大于等于d.
可以表达为:
$$
\begin{cases}
\frac{w^Tx^{(i)}+b}{||w||}\ge d \quad \forall y^{(i)}=1\
\frac{w^Tx^{(i)}+b}{||w||}\le -d \quad \forall y^{(i)}=-1\
\end{cases}
$$
将这两类点一类叫做1类,另一类为-1类,这样方便后续计算,但取什么值不影响,只要是两个不同值可以区分两类。
同时除以$d$ 得到进一步变形:
$$
\begin{cases}
\frac{w^Tx^{(i)}+b}{||w||d}\ge 1 \quad \forall y^{(i)}=1\
\frac{w^Tx^{(i)}+b}{||w||d}\le -1 \quad \forall y^{(i)}=-1\
\end{cases}
$$
此时分母$||w||d$ 是一个具体的数,可以进一步将其化简进式子中:
$$
\
\begin{cases}
w^T_dx^{(i)}+b_d\ge 1 \quad \forall y^{(i)}=1\
w^T_dx^{(i)}+b_d\le -1 \quad \forall y^{(i)}=-1
\end{cases}
\
w^T_d=w^T/(||w||.d)\
b_d=b/(||w||.d)
$$
因此上下两条直线方程分别为$w_d^Tx+b=1,w_d^Tx+b=-1$.中间的直线方程同时除以$||w||.d$ 也可以变为$w_d^Tx+b_d=0$ ,与之前的$w^Tx+b=0$ 是等价的,比如$2x+y=0$ 与$4x+2y=0$ 是等价的一个道理。
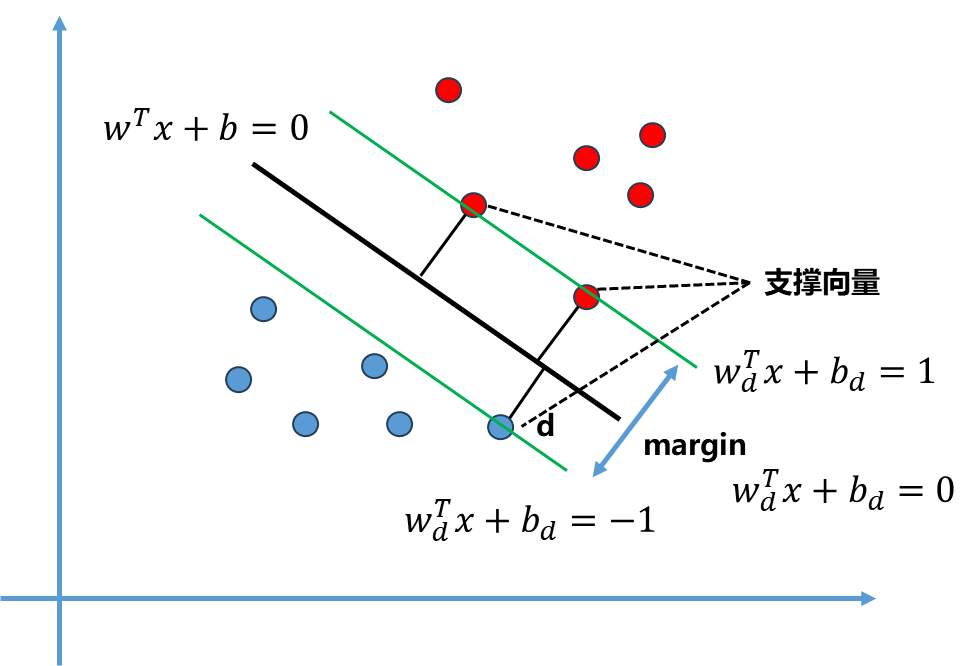
到这一步,所有的量都是$w_d$ 和$b_d$, 为了表达方便可以重新命名,将其替换为$w$ 和$b$ 表示:
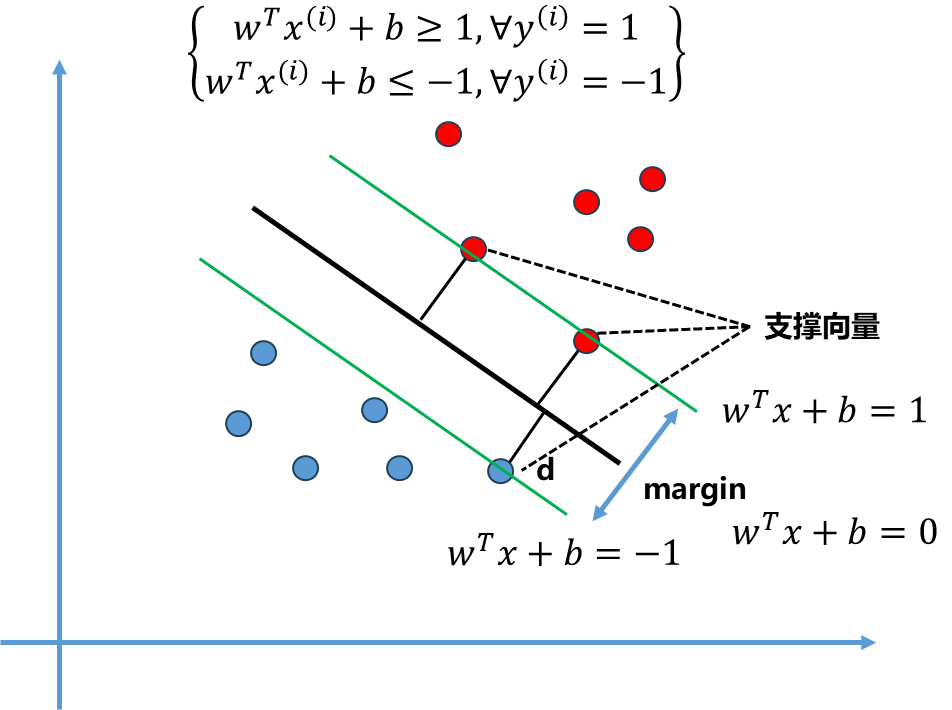
注意此时的$w$ 和$b$ 只是一个符号表示,和最开始的$w$ 的$b$ 理论上不是一个数了,差了一个$||w||.d$ 倍的系数关系.
观察此时两个式子,为了方便将其融合为一个式子:
$$
y^{(i)}(w^Tx^{(i)}+b)\ge1
$$
当$y^{(i)}=1$ ,就是原来上面的式子;当$y^{(i)}=-1$ ,就是原来下面的式子.因此这一个式子就表达了上面两个式子的关系。
此时再回想我们的目标:对于任意支撑向量$x$ , 最大化$d$ .
$$
max\quad d=\frac{|w^Tx+b|}{||w||}
$$
这个公式中的$x$ 代表某一个支撑向量,从上面的推导可知,支撑向量$x$ 代入到$w^Tx+b$ 这个式子中要么等于1要么等于-1,因此进一步可得:
$$
max\quad d=\frac{1}{||w||}\
$$
显然最大化$1/||w||$ 相当于:
$$
min\quad ||w||\
min \quad \frac{1}{2}||w||^2
$$
具体求解时一般写为$\frac{1}{2}||w||^2$ ,方便求导操作.
至此,整个SVM的目标就是:
$$
min \quad \frac{1}{2} ||w||^2\
s.t.\quad y^{(i)}(w^Tx^{(i)}+b) \ge 1
$$
可见SVM是一个有条件的最优化问题,而不是一个全局最优化问题. 在最优化领域加不加这个条件对问题求解的方法是大不相同的,如果是全局最优化没有任何条件,那么很简单直接对目标函数求导=0求解极值点即可。但是有条件就很复杂,需要Laplace算子求解。
求解上面这个式子的最优化问题解决的是一个Hard Margin SVM的问题,其背后假设数据是线性可分的。实际情况大多数据是线性不可分的,就需要用到Soft Margin SVM.
Soft Margin SVM
正则化本质是一个概念,并不是说对于所有的模型添加的正则化项都是同逻辑回归中介绍的那种L1、L2范式一样,有些模型要改变正则化的策略,但是对其正则化实现的效果是一样的。
Hard Margin SVM存在一个问题:
如上左图,它首先要保证能正确的分出这两类,此时的决策边界可能是图中所示黑线,这条黑线虽然将训练样本完美分开了,但是单看这个图我们不得不对其泛化能力产生怀疑。大多数蓝色点集中于左下角,只有一个蓝色点(红圈)在右上的位置,这个黑线决策边界显然非常强的受到这一个蓝色点的影响,但很可能这个蓝色点是一个outlier或者根本是一个错误的点,此时绿线可能是一个更好的决策边界。
绿线虽然将一个蓝色点错误的分类,但将其放到真实环境中其预测能力比黑线还要好,即泛化能力更强。更一般的情况,红圈蓝点位于更里面的位置(如上面右图),此时就完全线性不可分了.Hard Margin SVM就无法应用解决这种情况了,
所以我们需要思考一个机制使得SVM得到的决策边界要能够有一定的容错能力,泛化能力更高。
回顾一下Hard Margin SVM的目标;
$$
min \quad \frac{1}{2} ||w||^2\
s.t.\quad y^{(i)}(w^Tx^{(i)}+b) \ge 1\
\downarrow \
s.t.\quad y^{(i)}(w^Tx^{(i)}+b) \ge 1-\xi_i
$$
这个目标中$s.t.\quad y^{(i)}(w^Tx^{(i)}+b) \ge 1$ 的含义是任意一个点 都要在$w^Tx+b=1和w^Tx+b=-1$ 两根直线外,现在对这个条件进行宽松,让所有的点不一定非要在Margin区域外面,这个宽松量设为$\xi_i $ .
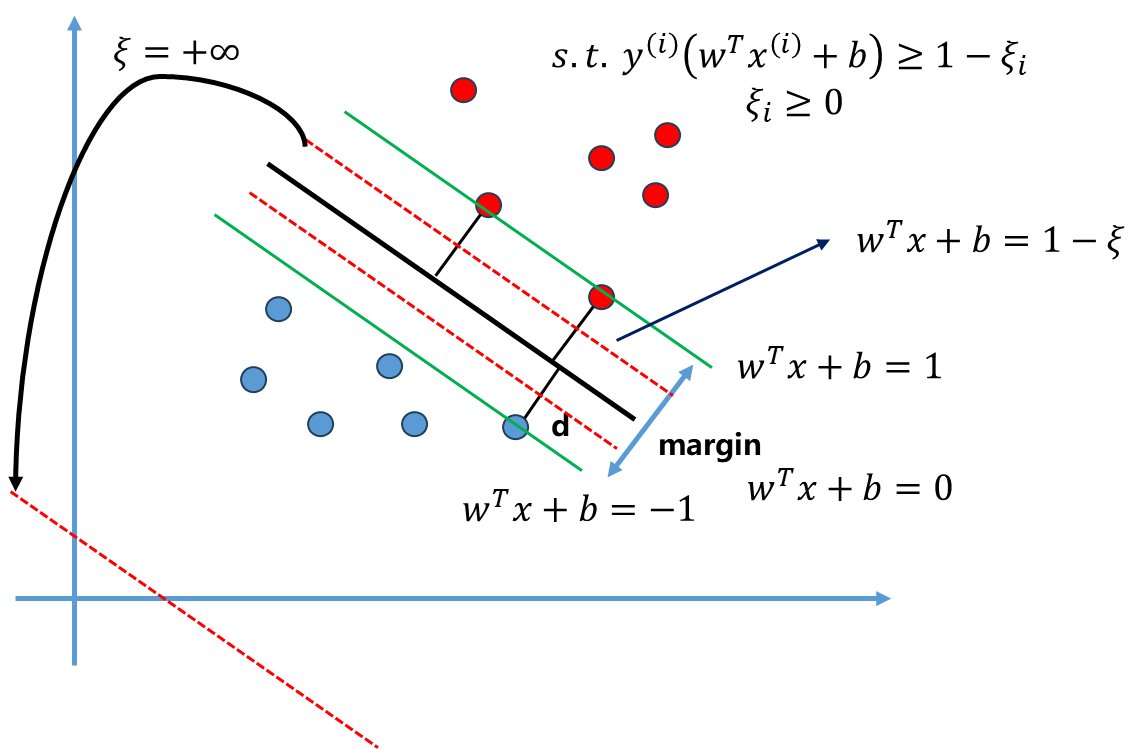
如上图所示,此时允许一些数据点位于黑线和红色虚线之间,即允许SVM犯一定错误。红色虚线对应方程为$w^Tx+b=1-\xi$ ,同时注意这个$\xi_i $ 不是一个固定值,而是对于每一个样本都有一个相应的$\xi_i$ ,如果有m个样本那么$\xi_i $ 相应有m个,即每个数据点都求出相应的容错空间。
但单单有这个条件还不够,如果$\xi $ 取正无穷,那么此时红色虚线就在无线远的右下角(如图中所示),所有点都满足这个条件,此时容错范围太大。
我们希望的是$\xi$ 有一定的容错空间,但容错空间不能太大,如何表征容错空间不能太大呢?很简单,在原目标上加上一项$\xi$ 的和,同时进行最小化。
因此完整的Soft Margin SVM表达式:
$$
min \quad \frac{1}{2} ||w||^2+C\sum_{i=1}^m\xi_i\
s.t.\quad y^{(i)}(w^Tx^{(i)}+b) \ge 1-\xi_i \
\xi_i \ge 0
$$
此时最小化目标函数既顾及了前半部分Hard Margin SVM,同时后半部分使得SVM可以容忍一定的分类错误,两者之间取得一个平衡。这里C为超参数,平衡两者占的比例。依然是一个有条件的最优化问题,具体求解过程略去(我也不会,没学过最优化原理,很难的哈哈)。
显然上面优化目标的后半部分可以看成一个L1正则项,同理也有L2正则:
$$
min \quad \frac{1}{2} ||w||^2+C\sum_{i=1}^m\xi_i^2\
s.t.\quad y^{(i)}(w^Tx^{(i)}+b) \ge 1-\xi_i \
\xi_i \ge 0
$$
从上面的表达式形式上看,它和前面提到的线性回归、逻辑回归的正则化项是一致,只不过具体的意思上$\xi_i$ 表达的几何意义和之前的$\theta_i$表示的几何意义是有区别的。
最后,上面的SVM最后求解得到的是一个线性方程,在二维平面就是一条直线,高维空间就是一个超平面。若何拓展解决非线性问题?
Scikit-learn中的SVM
使用SVM算法和使用KNN算法一样,要先对数据做标准化处理,因为SVM要最大化Margin,涉及到距离,如果数据点在不同维度上量纲不同的话,就会使得距离计算有一定的问题。
比如下图示例:
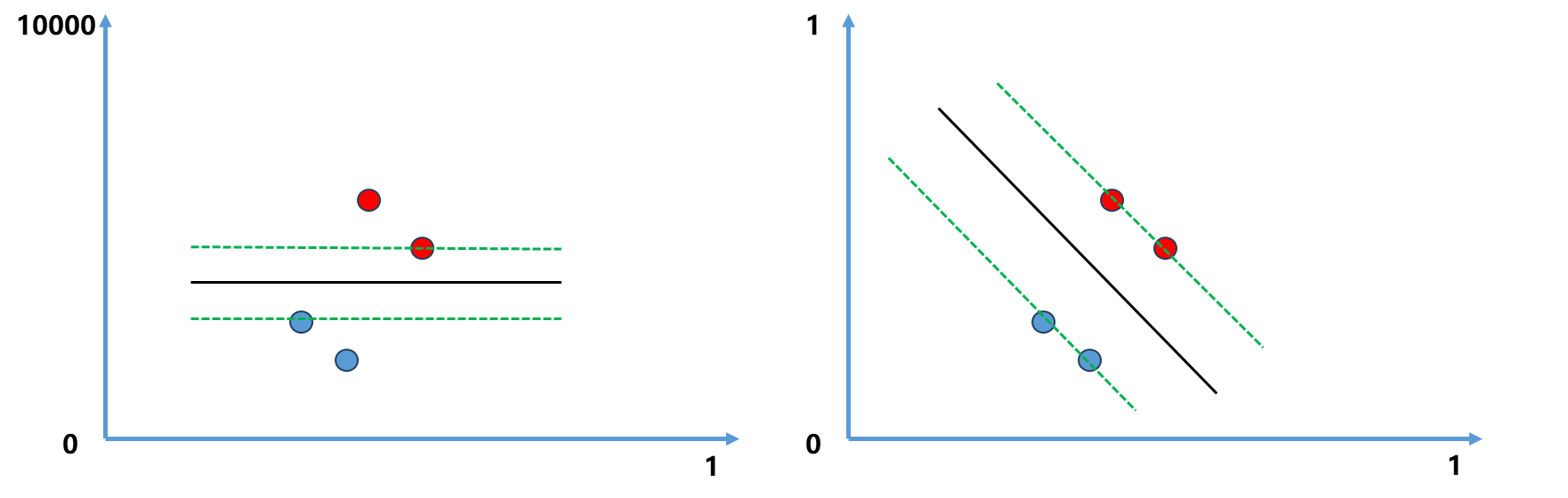
左图所示,如果某个维度如y轴范围为0-10000,会导致最终的决策边界时一条水平线;右图所示,而如果是0-1在同一个量纲内,决策边界就是一条斜线。
编程示例:
- 加载iris鸢尾花数据,方便可视化取前两个特征,前两类
1 | import numpy as np |
- 数据标准化
1 | from sklearn.preprocessing import StandardScaler |
使用Scikit-learn中的SVC进行分类,同时取超参数$C=1e9$ 此时相当于Hard Margin SVM,C越大容错空间越小.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25from sklearn.svm import LinearSVC
svc = LinearSVC(C=1e9)
svc.fit(X_standard, y)
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
plot_decision_boundary(svc, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[y==0,0], X_standard[y==0,1])
plt.scatter(X_standard[y==1,0], X_standard[y==1,1])
plt.show()
- 令超参数$C=0.01$ ,小一些,此时即Soft Margin SVM,观察现象
1 | svc2 = LinearSVC(C=0.01) |
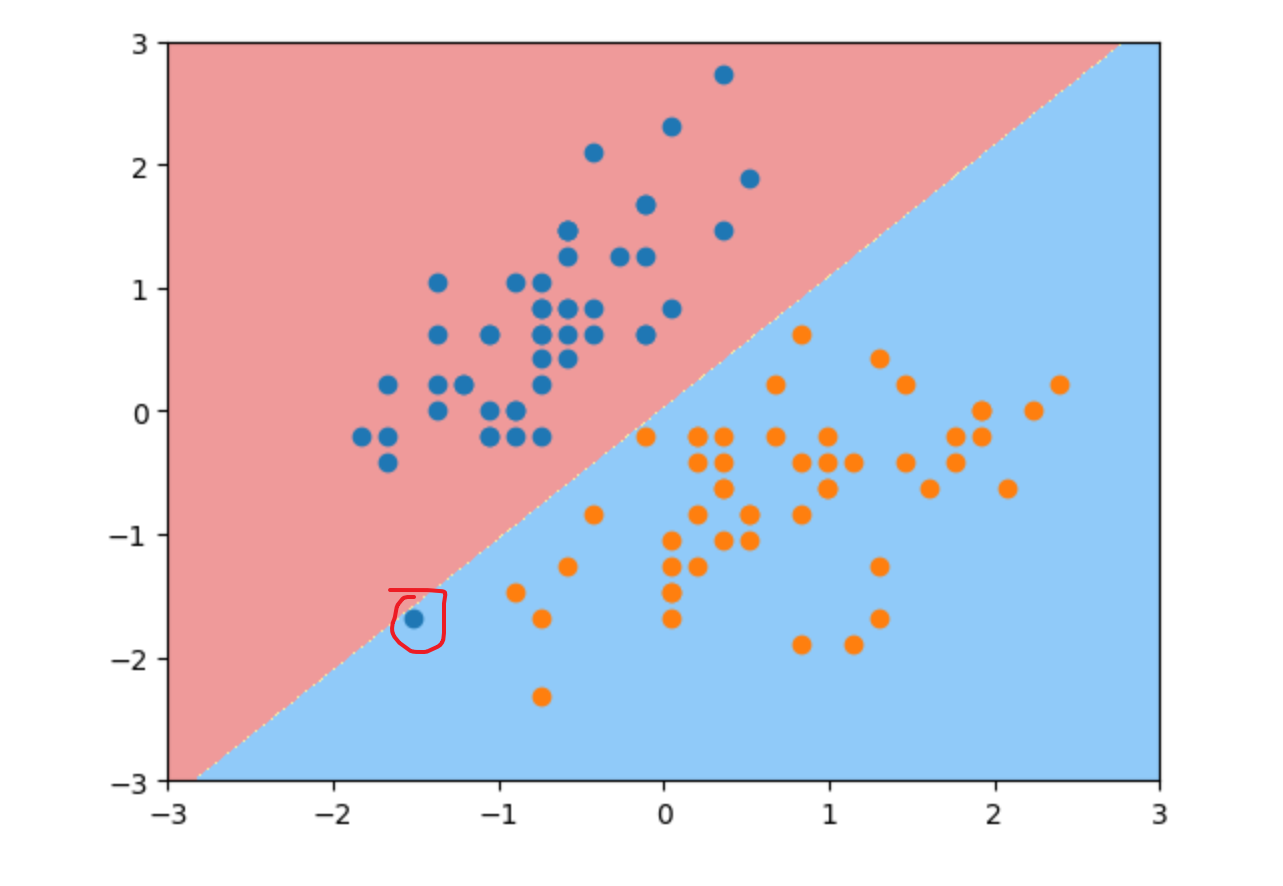
很明显上图红圈中有一个蓝色点被错误分类了,这就是将超参数$C$ 变小的结果即Soft Margin SVM,C越小容错空间越大。
- 接下修改一下绘图函数,观察两个不同C取值$C=1e9,C=0.01$ 即Hard Margin SVM和Soft Margin SVM此时的Margin区域。
1 | def plot_svc_decision_boundary(model, axis): |
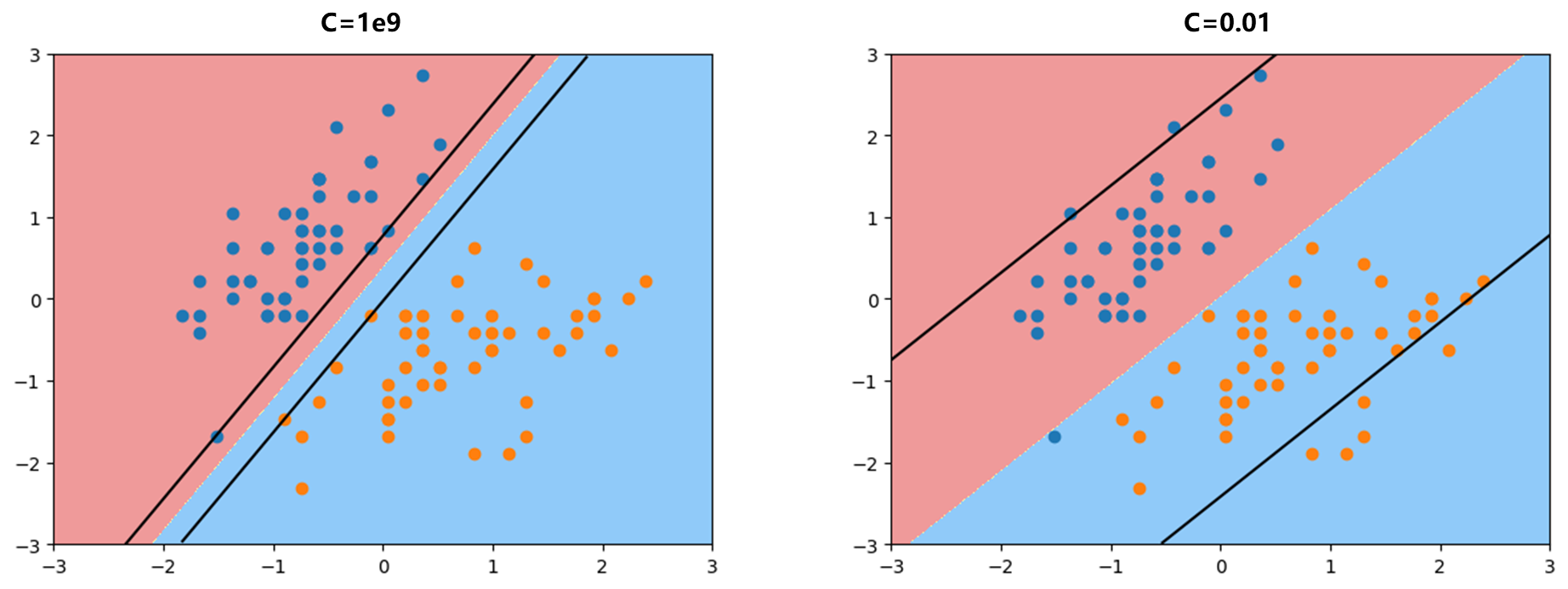
首先下面这段代码对应的就是两个支撑向量的直线方程$w_0x_0+w_1x_1+b=\pm1$ .
1 | up_y = -w[0]/w[1] * plot_x - b/w[1] + 1/w[1] |
同时观察上面左图对应Hard Margin SVM,margin区域内没有任何的点,支撑向量有三个蓝色点,两个橙色点;而右图对应Soft Margin SVM,margin区域内有很多点,有非常多容错空间。
SVM中使用多项式特征
上面是使用SVM线性分类的方式,加下来使用SVM处理非线性的问题。像前面多项式回归、逻辑回归一样,处理非线性问题最典型的一个思路就是使用多项式的方式扩充原有的数据创造新的特征。
编程示例:
- 使用sklearn生成虚拟数据
1 | import numpy as np |
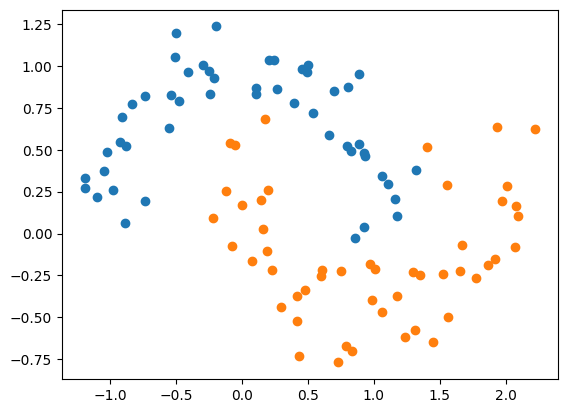
- 使用多项式特征的SVM(degree=3,C=1),使用方式跟之前基本一致
1 | from sklearn.preprocessing import PolynomialFeatures, StandardScaler |
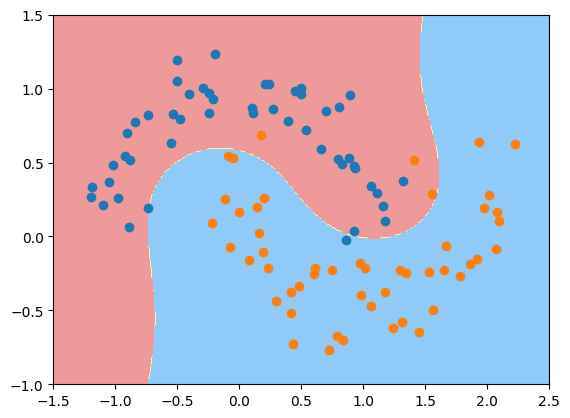
可见使用多项式特征的方式后决策边界不再是一条直线,是一条曲线。
对于SVM算法来说,在Scikit-learn封装中,可以不使用这种PolynoimalFeatures的方式来获取高维特征。SVM有一个特殊的方式可以直接使用这种多项式特征,这种方式称之为多项式核。
- 此时导入的是SVC而不是Linear_SVC
1 | from sklearn.svm import SVC |
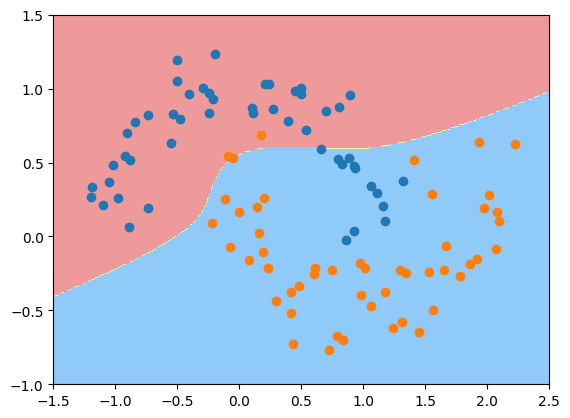
可以发现同样可以得到非线性的决策边界。那么什么是核函数?
核函数
SVM算法本质是求解下面的一个有条件的最优化问题:
$$
min \quad \frac{1}{2} ||w||^2+C\sum_{i=1}^m\xi_i\
s.t.\quad y^{(i)}(w^Tx^{(i)}+b) \ge 1-\xi_i \
\xi_i \ge 0
$$
求解这个最优化的问题过程中还需要对其进一步变形成数学上更好解的问题:
$$
max \quad \sum_{i=1}^{m}\alpha_i-\frac{1}{2}\sum_{i=1}^m \sum_{j=1}^m \alpha_i \alpha_jy_iy_j(x_ix_j) \
s.t.\quad 0\le\alpha_i\le C\
\sum_{i=1}^m\alpha_i y_i=0
$$
这一步是通过拉格朗日乘子法转化得到的,具体推导过程略。(如果有需要留言我会发出来)
上面这个式子中非常重要的一项是$x_ix_j$ ,可以发现这个式子对于样本数据集任意两个向量都要做点乘$x_ix_j$。
如果我们想使用多项式特征的话,按照之前的方式:
- 对$x^{(i)}$ 添加多项式特征使其变为$x^{,(i)}$
- 对$x^{(j)}$ 添加多项式特征使其变为$x^{,(j)}$
- 上面步骤结束后,我们就从$x_ix_j$ 变成了$x^{,(i)}x^{,(j)}$
核函数的思想是:先不将$x^{(i)},x^{(j)}$ 转变为$x^{,(i)},x^{,(j)}$ 后再做乘法,而是设置一个函数$K(x^{(i)},x^{(j)})=x^{,(i)}x^{,(j)}$,即传入$x^{(i)},x^{(j)}$ 然后直接计算出$x^{,(i)}x^{,(j)}$ .
因此上面式子进一步转换为:
$$
max \quad \sum_{i=1}^{m}\alpha_i-\frac{1}{2}\sum_{i=1}^m \sum_{j=1}^m \alpha_i \alpha_jy_iy_jK(x_i,x_j) \
s.t.\quad 0\le\alpha_i\le C\
\sum_{i=1}^m\alpha_i y_i=0
$$
K函数取不同的函数就相当于现在原始的样本上进行了变化后在进行乘法,K函数的作用就是直接省去了这一步,直接将原来的样本代入函数中,直接算出来$x^{,(i)}x^{,(j)}$ .
K函数就叫做核函数,又叫做kernel trick. 为什么这么说呢?因为即使我们不使用核函数也能完全能够达到同样的效果,它更像数学的一个技巧,把核函数应用在这里免去了将原来的样本先进行变形然后在对变形后的结果进行点乘这样的运算步骤,尤其是对于一些复杂的变形,使用kernel function会使得计算量减小,另一方面也节省了存储空间。我们对样本变形通常是将一个低维的样本变成一个更加高维的数据,存储高维的数据相应就会花很多的存储空间,使用核函数完全不用管样本变成什么样子, 不需要存储变化后的结果就可以直接使用核函数的方式计算出这二者的点乘结果。
同时注意核函数不是SVM算法本身特有的一种trick,事实上只要算法转化成了一个最优化问题,在求解这个最优化问题中存在$x_i.x_j$ 这样的式子或者类似这样的式子,我们都可以相应的应用核函数技巧。
以多项式核函数为例看看核函数如果应用的:
$$
K(x,y)=(x.y+1)^2\
=(\sum_{i=1}^nx_iy_i+1)^2\
=\sum_{i=1}^n(x_i^2)(y_i^2)+(\sum_{i=2}^n\sum_{j=1}^{i-1}(\sqrt{2}x_ix_j)(\sqrt{2}y_iy_j)+(\sum_{i=1}^n(\sqrt{2}x_i)(\sqrt{2}y_i)+1
$$
从上面式子可以发现$x$ 先变成了$x^,=(x^2_n,…,x^2_1,\sqrt{2}x_nx_{n-1},\sqrt{2}x_n,\sqrt{2}x_1,1)$ ,同理$y$ 变成了这样的$y^,$ ,这两个新的向量相乘再相加的结果就是上面的式子。
即有:
$$
K(x,y)=x^,.y^,
$$
$x^,$的定义其实就是将原来的$x$ 添加了2次项的数据后得到的结果。
再来体会一下,我们原本是要将$x$ 先变成$x^,=(x^2_n,…,x^2_1,\sqrt{2}x_nx_{n-1},\sqrt{2}x_n,\sqrt{2}x_1,1)$,$y$ 变成$y^,=(y^2_n,…,y^2_1,\sqrt{2}y_ny_{n-1},\sqrt{2}y_n,\sqrt{2}y_1,1)$ ,然后做$x^,.y^,$ .但有核函数我们不需要表示这一步了,直接用原来的样本数据代入到$K=(x.y+1)^2$ 就好了,这和上面先变换后点乘的结果是一致的。这就是核函数的优势,大大降低计算复杂度。
通过上面2维核函数可推得高维多项式特征的核函数:
$$
多项式核函数: K(x,y)=(xy+c)^d
$$
同时如果我们理解了核函数就是在替换原来样本$x.y$ 点乘操作,我们就可以用这种思路表示线性SVM:
$$
线性核函数: K(x,y)=x.y
$$
RBF核函数
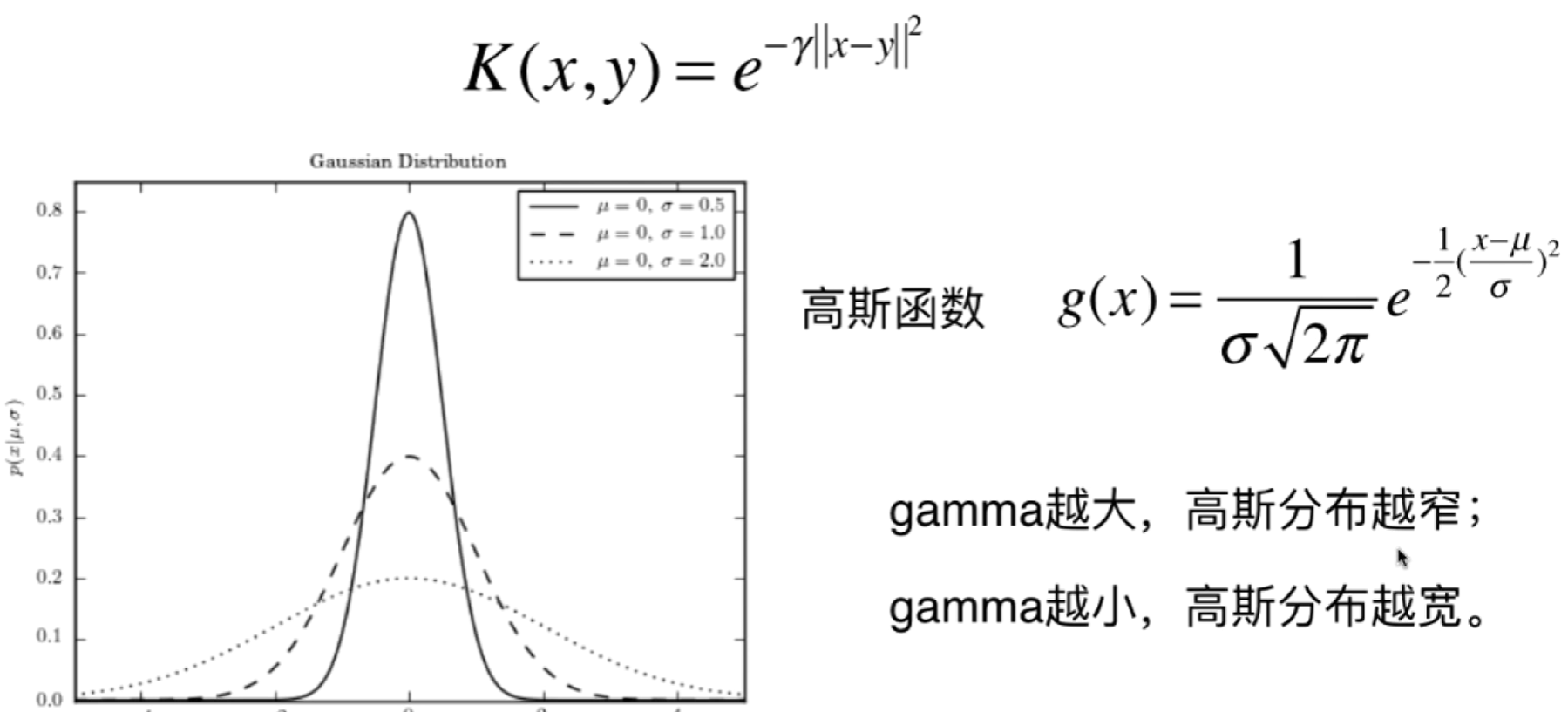
高斯核函数
SVM算法使用最多的一种核函数叫做高斯核函数。核函数$K(x,y)$ 通常表示$x$ 和$y$ 的点乘,高斯核函数的一般表示形式:
$$
K(x,y)=e^{-\gamma||x-y||^2}\
$$
其中$\gamma$ 是超参数. 我们学过概率论知道正态分布高斯函数的表达式为$g(x)=\frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{1}{2}(\frac{x-\mu}{\sigma})^2}$ ,两者形式是相同的。
高斯核函数有时候也叫做RBF核函数,RBF英文全称为Radial Basis Function Kernel.有时候中方翻译叫径向基函数。
对于我们的多项式核函数来说,本质是将所有的数据点添加了多项式项,再将这些有了多项式项的新的的数据特征进行点乘就形成了多项式核函数。那么高斯核函数本质也应该是将原来的数据点映射成为一种新的特征向量,然后是这个新的特征向量点乘的结果,事实正是这样。只不过高斯核函数表达的数据映射是非常复杂的,其本质是将每一个样本点映射到一个无穷维的特征空间。
虽然高斯核函数的变形是非常复杂的,但经过变形在点乘得到的结果却是非常简单的,就是我们上面的式子,也再次能看出来核函数的威力,大大降低计算复杂度。
接下来尝试理解一下高斯核函数到底在做什么事情?
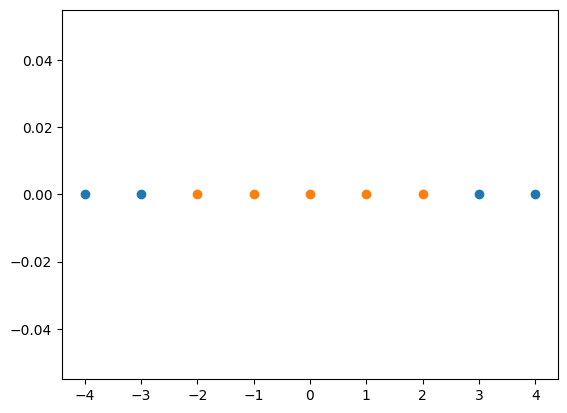
先回忆一下为什么使用多项式特征可以处理非线性的数据问题,其基本原理是靠升维使得原本线性不可分的数据线性可分。比如原本的数据只有一个维度$x$ ,现在为每个数据添加一个$x^2$ 这样就可能使得原本线性不可分的数据线性可分(如下图)。
高斯核本质上也是做的上面的事情:
$$
K(x,y)=e^{-\gamma||x-y||^2}\
$$
高斯核式子中原本是$||x-y||^2$ ,现在将$y$ 的值固定一下,将$y$ 的值不取样本点而取固定点如下图的$l_1$和$l_2$, 这两个点英文通常叫做$landmark$ .高斯函数的升维过程是对于原本的每一个$x$ 的值,如果有两个landmark,就升维到2维的样本点,具体取值:
$$
x\rightarrow(e^{-\gamma||x-l_1||^2},e^{-\gamma||x-l_2||^2})
$$
这样就将原本一维的样本点映射到了2维空间。
编程示例:
- 生成 一维数据
1 | import numpy as np |
- 使用高斯核函数进行升维
1 | def gaussian(x, l): |
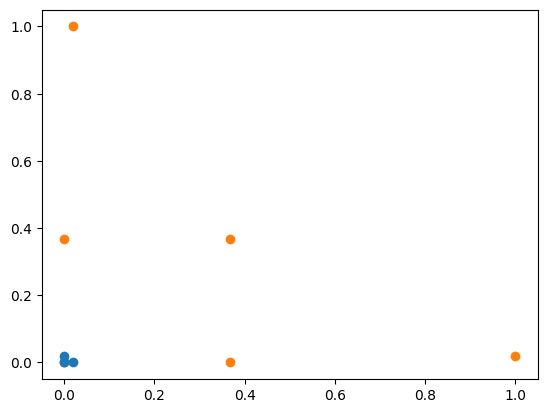
显然此时数据升维后是线性可分的。
上面我们是将高斯核中的$y$ 固定成地标点$l_1, l_2$ ,但实际上高斯核$K(x,y)=e^{-\gamma||x-y||^2}$ 中的y代表每一个数据点,即高斯核对于每一个数据点都是landmark,其取的地标点比我上面只取两个地标点要多的多,有多少个样本取多少个地标点。
因此高斯核是将一个$mn$ 的数据映射成了$mm$ 的数据,如果我们的样本数据m非常大,因此经过高斯核函数我们就映射成了一个非常高维的数据,因为样本数据有无穷多个,因此可以映射为无穷维空间。
显然如果m<n,此时使用高斯核函数就非常划算了,最典型的应用领域就是NLP。
scikit-learn中的高斯核函数
对比正态分布的表达式和高斯核函数的表达式可知,$\gamma$ 就代表$-\frac{1}{2}\frac{1}{\sigma^2}$ ,因此
- $\sigma$ 越小,$\gamma$ 越大,分布图就越窄越尖
- $\sigma$ 越大,$\gamma$ 越小,分布图就越宽越胖
编程示例:
- 加载数据
1 | import numpy as np |
- 使用Scikit-learn中的SVC(这里代码示例传入$\gamma$ =1)
1 | from sklearn.preprocessing import StandardScaler |
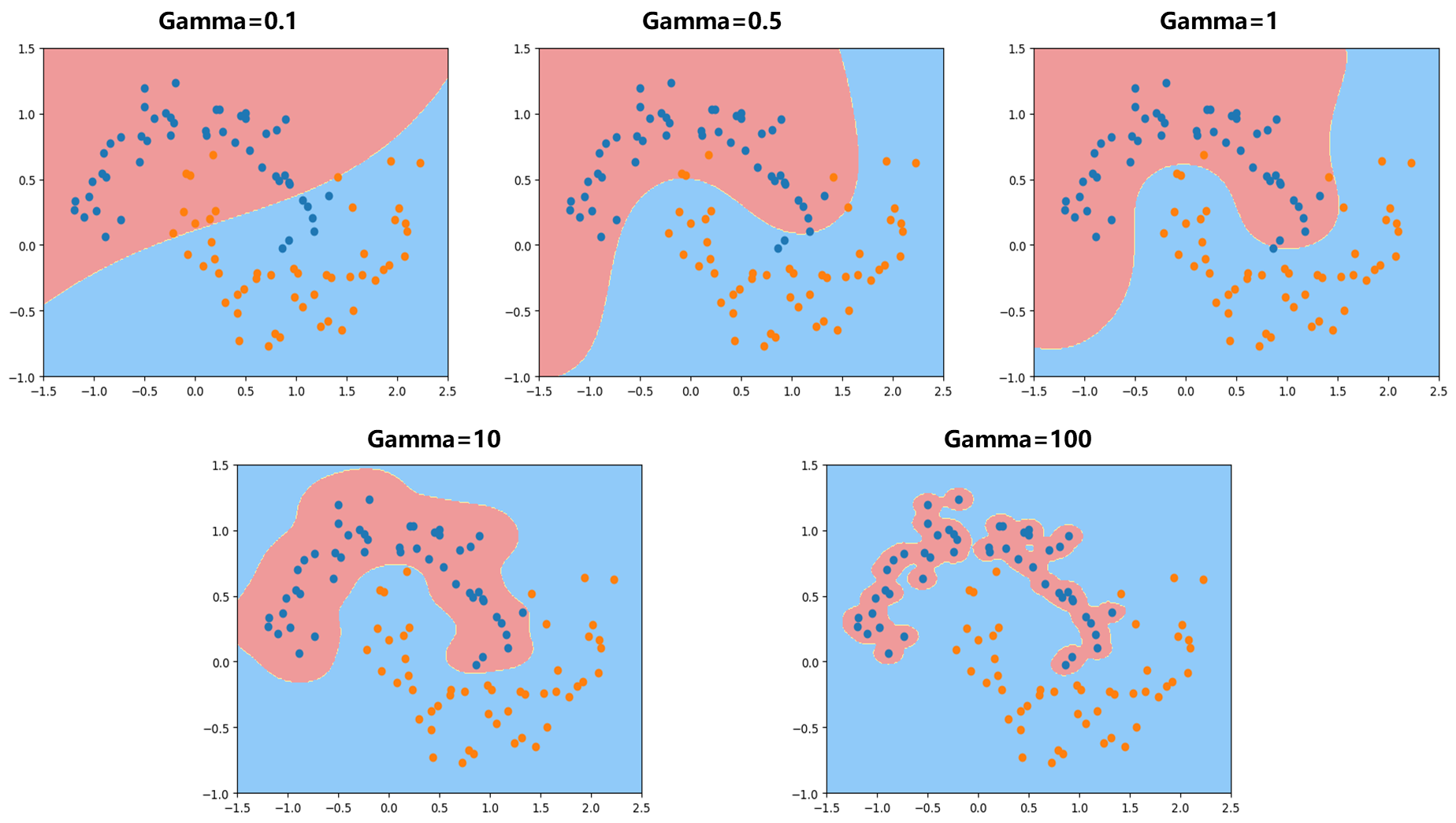
可见$\gamma =100$ 越大,针对某一类的样本点周围都形成了钟形的图案,可以看成俯视整个图案,蓝色点都对应钟形图案的一个尖,蓝色决策边界整体比较窄,显然过拟合。较少$\gamma=10$ ,可见钟形图案变宽。不断减小$\gamma$ 变的更宽了。
SVM解决回归问题
回归问题本质是找到一条直线或者曲线最佳程度的拟合我们的数据比如下图红线,在这里怎么定义”拟合”就是不同回归算法的关键。比如前面的线性回归算法定义拟合的方式是将数据点到预测点的MSE最小。
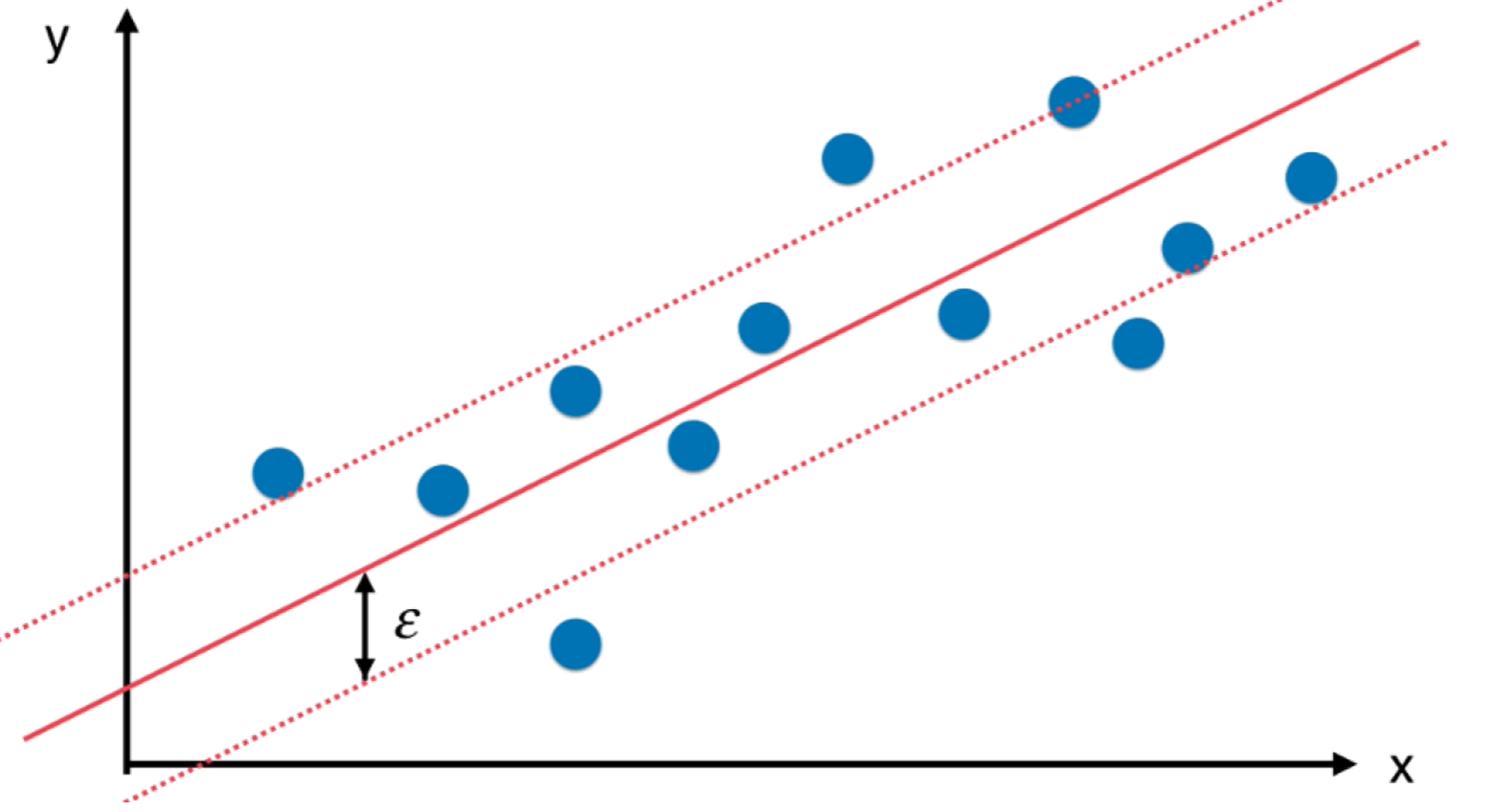
而SVM的拟合定义是另外一个定义,要指定一个Margin值,与分类问题不同,我们希望此时Margin区域内包含的样本点越多越好,如图中的红色虚线。具体训练SVM回归问题时需要对Margin区域有一个指定,引入超参数$\epsilon$ .
代码示例:
1 | import numpy as np |