
Random Forests
集成学习
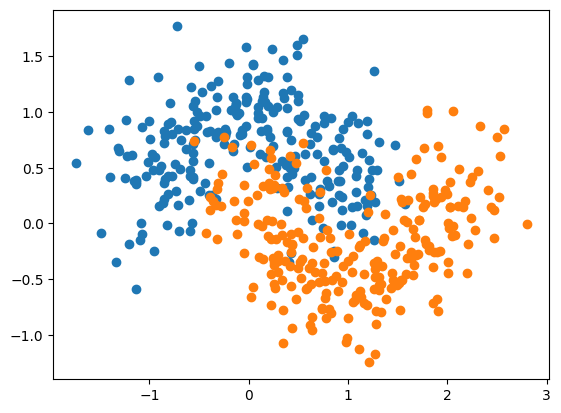
《EVA》中有一台超级电脑叫做MAGI,MAGI 系统由三台拥有不同人格与思维方式的超级计算机组成,分别代表三种身份:科学家的理性思维、母亲的情感判断以及社会女性的现实考量。在面临复杂决策时,三台计算机会各自独立分析并得出判断,随后通过多数投票机制决定最终结果。这种机制恰好对应了机器学习中的**集成学习(Ensemble Learning)**思想——即通过整合多个具有差异性的模型(基学习器),让它们从不同角度“看待问题”,再通过投票或加权融合的方式综合决策,从而降低单个模型的偏差和方差,提高整体的鲁棒性与预测精度。
生活中也有很多集成学习的例子。比如买东西找别人推荐,通常我们不会只招一个人推荐,会找很多人推荐来看他们综合的意见。像是买车、买房子、出国留学这些事我们都会潜意识使用这种集成学习的方式,综合多方面的意见,因为每个人的经历不同视角不同他们给出决策背后的原因可能不同,集成更多人的意见通常情况最终得到的决策是最合适的。
面对一个问题的时候,我们可以将不同的算法针对这同一个数据都跑一遍看看它们最终的结果是怎么样的,最终使用投票的方式少数服从多数。Scikit-learn为此提供了方便的接口叫做Voting Classifier.
代码示例:
- 加载虚拟数据
1 | import numpy as np |
算法1:先使用Logistic Regression算法
1
2
3
4
5
6
7
8
9from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
from sklearn.linear_model import LogisticRegression
log_clf = LogisticRegression()
log_clf.fit(X_train, y_train)
log_clf.score(X_test, y_test)得到Score为0.864。
算法2:使用SVM算法
1
2
3
4
5from sklearn.svm import SVC
svm_clf = SVC()
svm_clf.fit(X_train, y_train)
svm_clf.score(X_test, y_test)得到Score为0.896。
算法3:使用决策树算法
1
2
3
4
5from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(random_state=666)
dt_clf.fit(X_train, y_train)
dt_clf.score(X_test, y_test)得到Score为0.864。
综合三种算法进行投票
1
2
3
4
5
6
7
8
9y_predict1 = log_clf.predict(X_test)
y_predict2 = svm_clf.predict(X_test)
y_predict3 = dt_clf.predict(X_test)
y_predict = np.array((y_predict1 + y_predict2 + y_predict3) >= 2, dtype='int')
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict) # 0.904二分类问题结果为0或1,这里采用的将三个预测结果y_predict1、y_predict2、y_predict3相加,如果有两个以上的模型认为其分类为1,那么最终结果将会$\ge2$ ,对应于上面的代码。最终得到accuracy_score为0.904比单独使用上面三种算法都要好好。
接下来使用Scikit-learn的接口Voting Classifier完成这个过程:
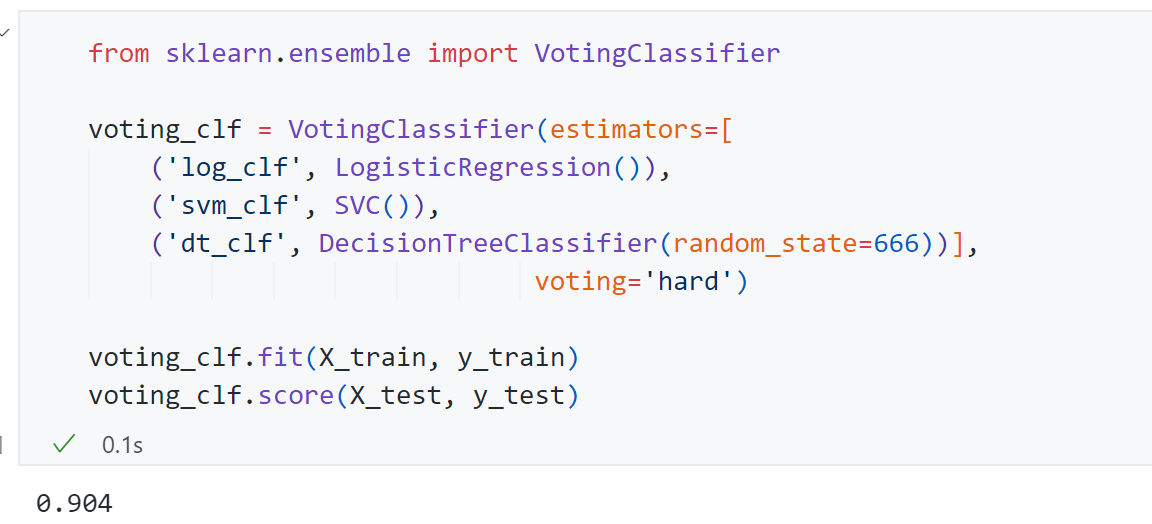
最终得到score为0.904,与上面结果一致。这里有个参数voting=”hard”,Hard Voting Classifier是让多个模型分别对同一数据进行预测,然后采用少数服从多数的原则,以投票最多的类别作为最终结果。它不考虑模型预测的概率,只依据各模型的最终分类标签进行决策。
Soft Voting Classifier
上面少数服从多数的方式叫做Hard Voting,还有一种更重要的方式叫做Soft Voting ,其背后想法也非常简单,因为在大多数情况下少数服从多数并不是最合理的。
更合理的投票,应该有权值。比如唱歌比赛的投票,专业的音乐评审他们的分值就应该高一些,而普通的观众投票分值就应该相应低一些。
举个例子,假设当前的Voting Classifier集成了5个模型,针对一个二分类问题,下面5个模型的预测概率如下图所示:
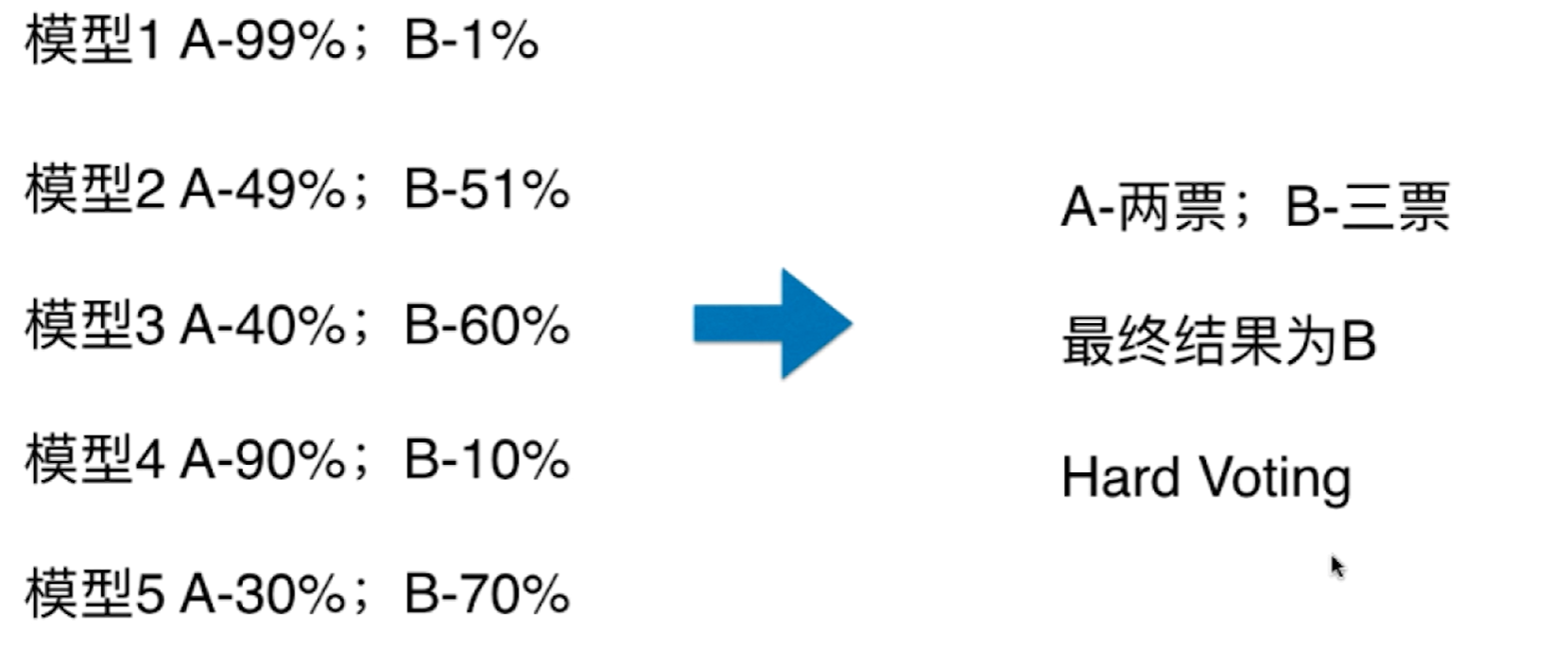
从Hard Voting的方式出发,如果只看最终的结果,那么A类为2票,B类为3票,最终投票结果为B. 但从数值上看这样投票有些问题,虽然只有模型1和模型4将数据分为A类,但是其概率分别为99%,90%,可以说近乎非常确定我们的样本是A类。相应的虽然有三个模型将样本分为B类,但是它们的概率分别为51%、60%、70%,因此在这种情况下虽然A类的票数少,但其权值应该更高一些。
Soft Voting就是基于这种思路,其将模型把这个数据分为不同类的概率当作票数的权值计算,计算两类的概率平均值:
$$
A-(0.99+0.49+0.40+0.90+0.30)/5=0.616\
B-(0.01+0.51+0.60+0.10+0.70)/5=0.384\
最终结果为A
$$
同样如果要使用Soft Voting, 那么在这个集成学习中要求集合的每一个模型都能估计概率。在此回顾一下前面的机器学习分类算法是否都支持估计概率:
- Logistic Regression本身就是基于概率模型的,用到$\sigma$ 函数输出结果为0-1之间的概率
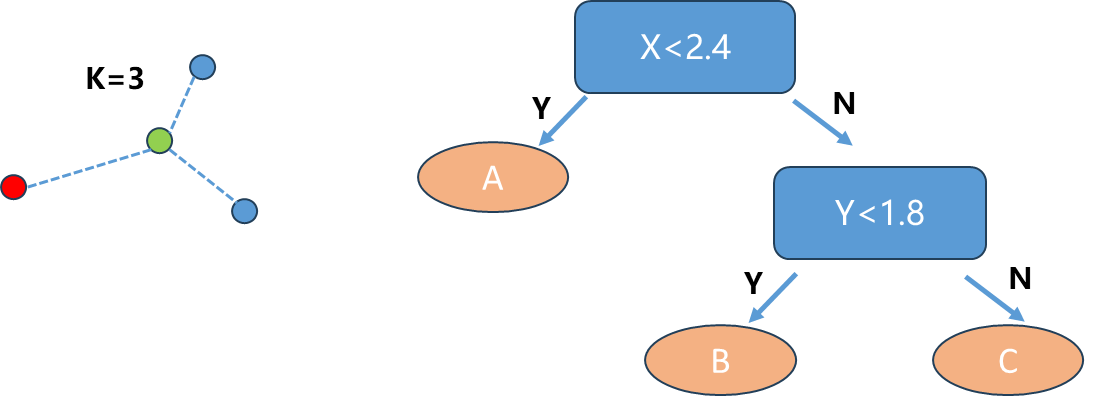
- KNN算法通过寻找最近邻的K个点,比如下图K=3,蓝色2票,红色1票,那么相应概率分别为66.6%,33.3%.同样KNN也可以考虑权值,可以通过前面讲KNN时考虑距离来进行加权求解
- 决策树算法它计算概率的方式和KNN类似,训练阶段时通常一个叶子节点会包含多个类别的数据,概率也就是占比例最大的类的数量除以叶子节点的总数量就是判断其属于这个类的概率
- SVM也可计算出概率,不过过程比较复杂
Soft Voting代码示例:
- 使用数据同上面(代码同上)
- Soft Voting Classifier(令 voting=’soft’)
1 | voting_clf2 = VotingClassifier(estimators=[ |
最终得到score为0.912.比Hard Soft voting Classifier要好.
Bagging和Pasting
集成学习通过集成多个算法,让不同的算法对同一组数据进行分析得到结果,最终投票来看哪个结果是大家公认更正确的更好的。但是依然存在一个问题:虽然有很多机器学习算法,但是从投票角度看,仍然不够多,如果想要尽量保证最终有一个好结果,我们希望有更多的投票者成百上千甚至上万的投票者。所以我们需要创建更多的子模型,来集成更多子模型的意见,而且这些子模型之间不能一致,子模型之间要有差异性。
如何创造更多的子模型并且让它们之间保持差异性呢?一个简单的思路是让每个子模型只看样本数据的一部分,假如只有500个样本数据,那么我们训练的时候让每个子模型只看100个样本数据,相应每个子模型的算法可以是共同的一个算法。
显然这些的话每个子模型准确率肯定会降低,因为只用到了100个数据。但是集成学习集成了很多子模型来投票决定最终的分类结果,这个过程中每个子模型并不需要太高的准确率。
举个例子:
针对二分类问题,如果每个子模型只有51%的准确率:
- 如果只有1个子模型,整体准确率为51%
- 如果只有3个子模型,整体准确率为$0.51^3+C_3^20.51^20.49$ 即51.5%
- 如果只有500个子模型,整体准确率为$\sum_{i=251}^{500}C_{500}^{i}(0.51)^i(0.49)^{500-i}$ 即65.6%
随着子模型数量增加,那么相应的集成学习整体模型准确率不断上升。
每个子模型只看样本数据的一部分,在这里就有一个差异,有两种方式来看样本数据的一部分:
- Bagging: 放回取样, 比如子模型从500个样本看100个样本,然后放回去下个子模型继续从从500个样本看100个样本
- Pasting: 不放回取样,比如子模型从500个样本看100个样本,那么下个子模型只能从剩下的400个样本看100个样本
通常来说Bagging更常用,因为如果使用Pasting针对上面例子只能得到5个子模型数量太少,采用Bagging可以训练成百上千的子模型。同时Bagging不依赖于随机,如果使用Pasting不放回去等同于500个样本分成了5份,每一份有100个样本,怎样分将非常影响我们最终的pasting集成学习得到的结果,但是Bagging每一次从500个样本取100个样本学习的过程重复了非常多次,一定程度将这个随机过程所带来的问题给取消了。统计学中将放回取样叫做bootstrap.
代码示例:
数据依旧同上
使用sklearn中的Bagging,这里选用决策树,决策树非参数学习模型更能产生差异相对比较大的子模型
1 | from sklearn.tree import DecisionTreeClassifier |
其中n_estimators参数代表即集成几个决策树模型,max_samples=100代表每个子模型看多少样本数据,bootstrap=True这个控制是放回取样还是不放回取样。
1 | from sklearn.tree import DecisionTreeClassifier |
n_estimators=500时即有500个决策树子模型,此时score为 0.912;n_estimators=5000时即有5000个决策树子模型,此时score为 0.92.
OOB
OOB英文全称Out-of-Bag, 放回取样可能会导致一部分样本没有取到,平均大约有37%的样本没有取到。这些没取到的样本通常就叫做Out-Of-Bag.那么我们在使用Bagging这种集成学习时,就不需要使用测试集了,而使用这部分没有取到的样本做测试/验证。
相应的scikit-learn有oob_score_属性来直接 得到使用OOB作为测试集的结果。
代码示例:
数据依旧同上
只需在原来基础上添加一个oob_score=True的参数
1 | from sklearn.tree import DecisionTreeClassifier |
得到结果为0.918.
n_jobs
Bagging的思路显然非常容易并行化处理,我们是独立的训练若干个子模型,对于每个子模型都是从500个样本取100个样本,取样本过程也是独立的,因此非常方便并行处理。scikit-learn中 可以并行的算法都是传入n_jobs 的参数,传入几个相应就使用计算机的几个核,如果传入-1就是使用所有的核。
比较用时:
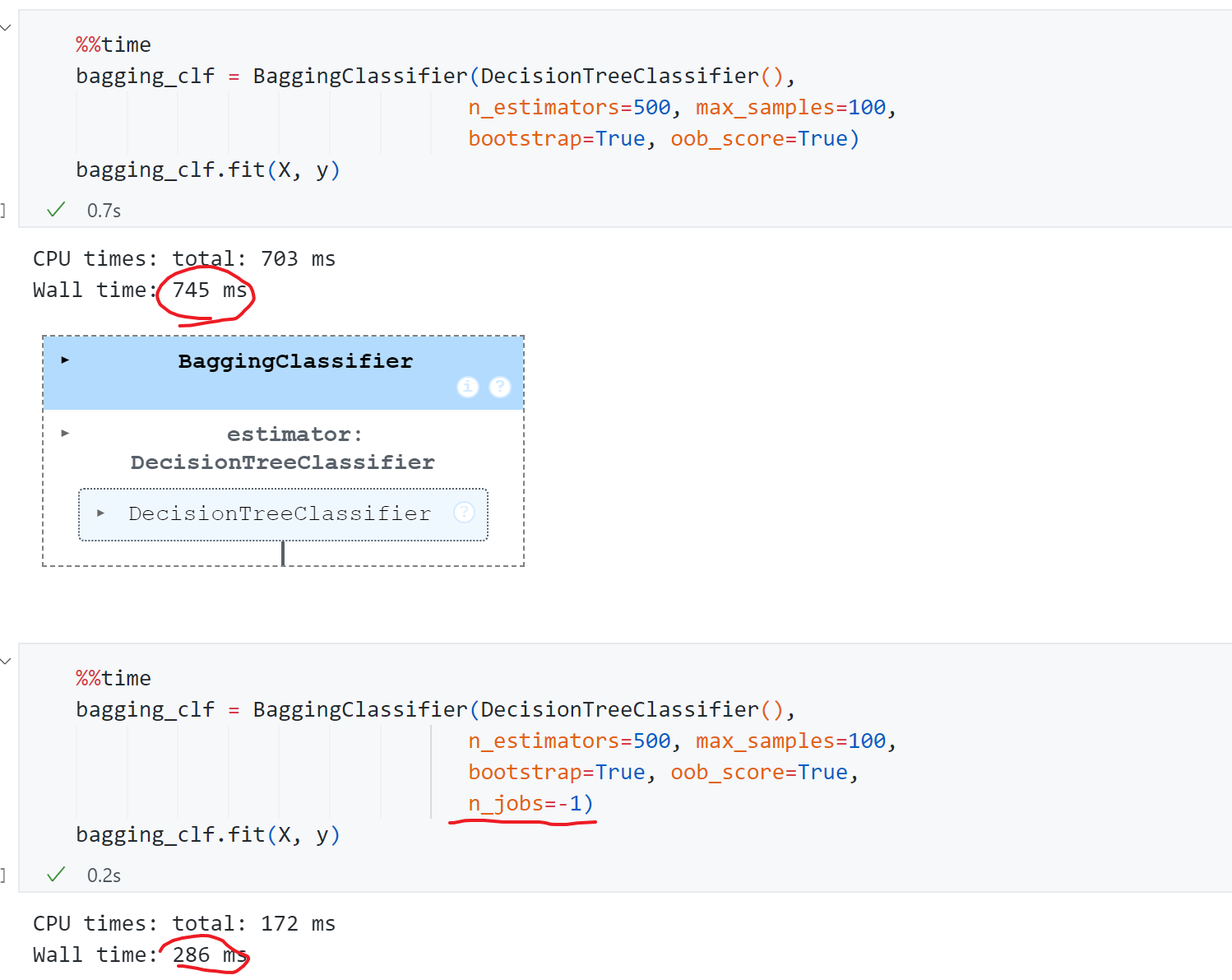
可见传入n_jobs=-1后用时286ms,比开始快了2-3倍。
Random Patches
前面我们让每一个子模型产生差异化的方式是让每一个子模型都去看更小的一个样本数据集,其实还有其它的差异化方式。一个非常重要的方式针对特征随机采样-Random Subspaces.
如果既针对样本数量,又针对特征空间进行随机采样,综合起来叫做Random Patches. 我们数据本身就是一个矩阵(如下图), 每一行代表一个样本,每一列代表一个特征。Random Patches则既在行的维度上随机,又在列的维度上随机。

特征空间上的随机采样又可以叫做$bootstrap_features$ ,这也是Scikit-learn留的一个接口名字。
代码示例:
1 | random_subspaces_clf = BaggingClassifier(DecisionTreeClassifier(), |
其中max_features=1代表现在对特征随机取样最多看多少个特征,与max_samples含义类似。 bootstrap_features=True ,表示对特征放回采样的方式。这里max_features=1因为 这个虚拟数据只有两个维度,max_samples=500等于我们的样本数,此时相当于没有对样本数据进行随机,此时就是random_subspaces。 最终score为0.812。
1 | random_patches_clf = BaggingClassifier(DecisionTreeClassifier(), |
令max_samples=100,此时相当于既针对样本数量,又针对特征空间进行随机采样即Random Patches。最终score为0.852.
这种Bagging_cls集成了大量的决策树,这种集成方式还有一个非常形象的名字就叫做随机森林。
随机森林
前面实现的Bagging Classifier包括Random Subspaces Classifier 或Random Patches Classifier ,只要使用的Base Estimator是决策树的话都可以叫做随机森林。不过Scikit-learn还专门封装了一个随机森林的类,并且提供了更多的随机性。
代码示例:
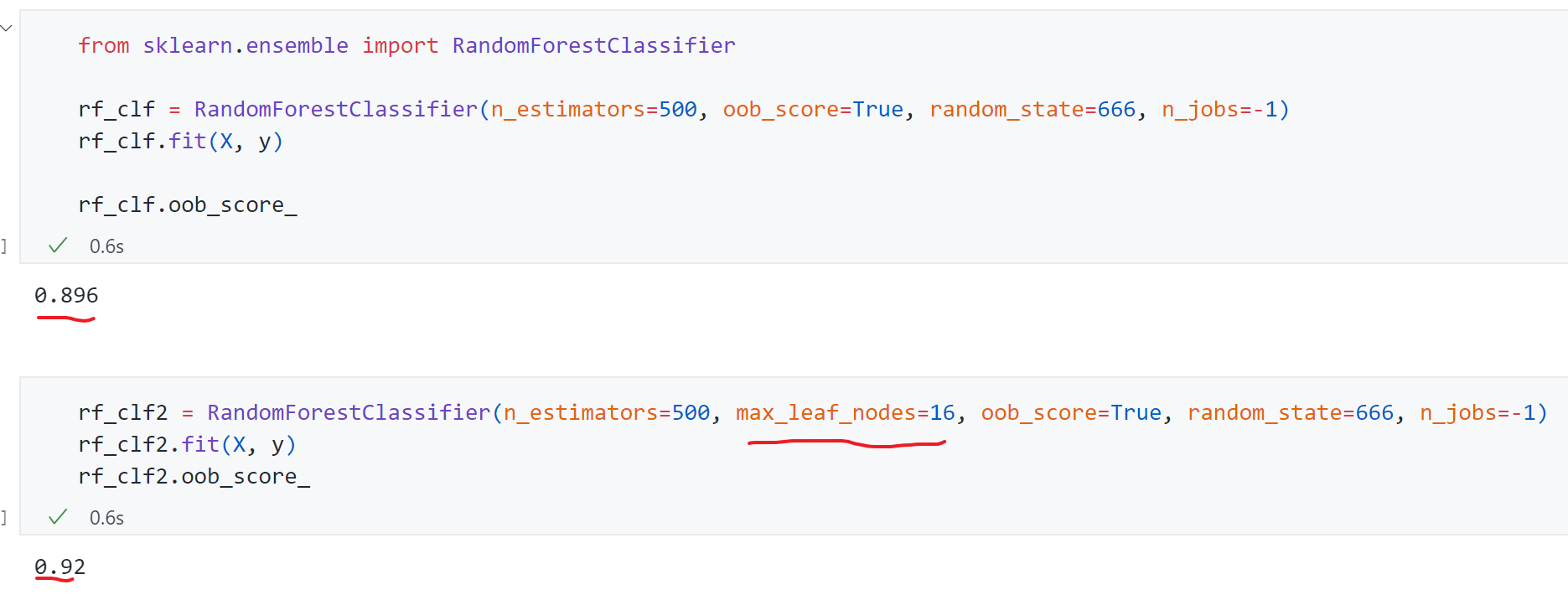
其中有个参数max_leaf_nodes代表一棵决策树最多有多少叶子节点。随机森林拥有决策树和BaggingClassifier的所有参数.
Extra-Trees
和随机森林非常类似的还有另外一种方法,叫做Extra-Trees.极其随机的森林,表现在决策树节点划分上使用随机的特征和随机的阈值,这样每一棵决策树差异就会更加的大。
1 | from sklearn.ensemble import ExtraTreesClassifier |
这种方式提供了额外的随机性,能够抑制过拟合现象,但增大了bias.同时训练速度更快。
如果使用集成学习解决回归问题,可以采用下面模块:
1 | from sklearn.ensemble import BaggingRegressor |
Boosting
前面所涉及的集成学习模型大多数都是独立的集成多个模型,对于每一个模型我们将其在视角上有一定差异化,最终综合这些有差异化的模型的结果。
另外一类非常典型的集成学习的思路叫做Boosting,也要集成多个模型,和Bagging不同,Boosting中的每个模型之间彼此不是一个独立的关系,而是一个相互增强的关系。
Ada Boosting:
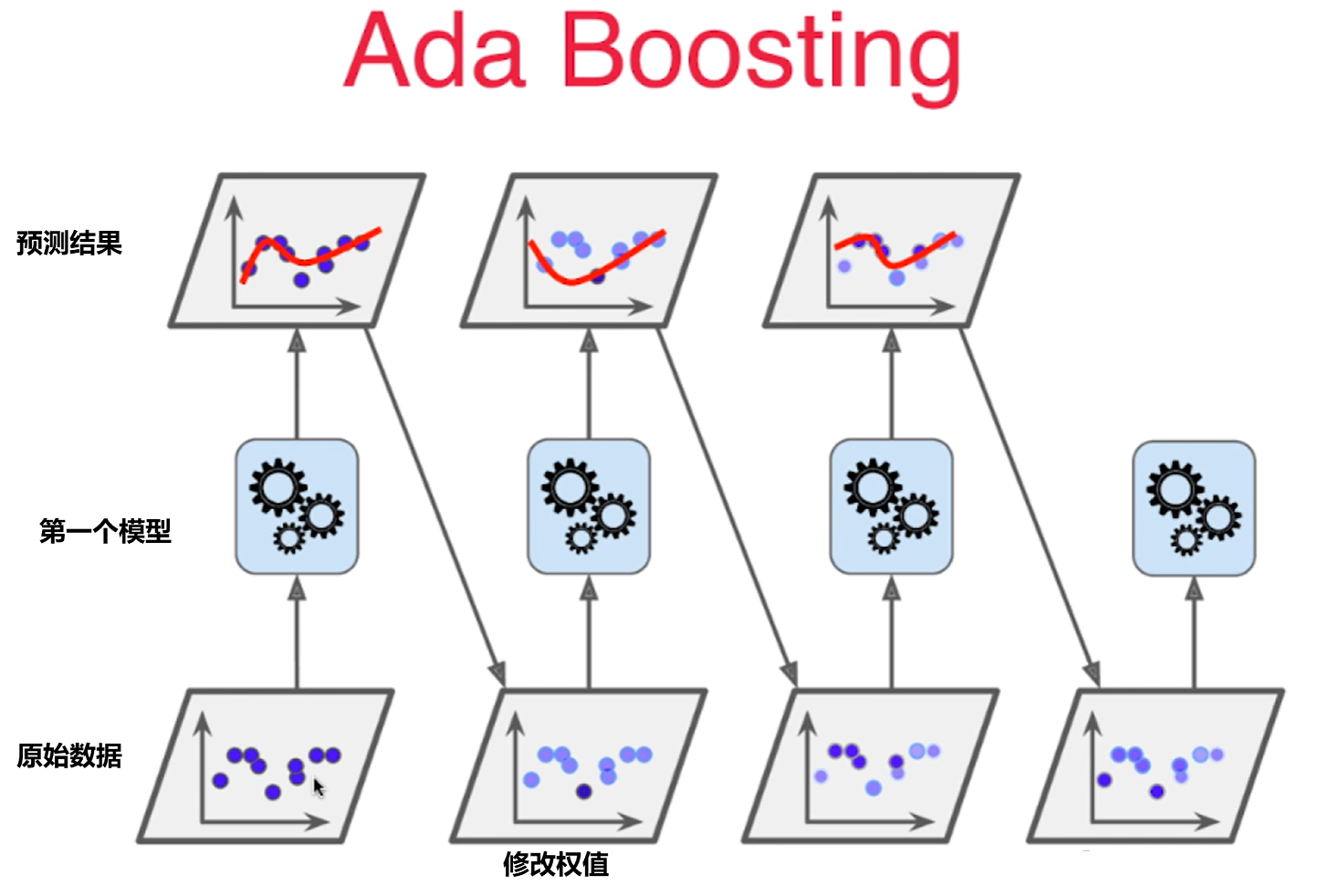
假设一个回归问题,我们有原始数据,然后通过第一个模型对原始数据学习,相应得到了深色和浅色的点(第三行第2张图)。浅色点是被第一个模型预测成功的点,深色的点与预测的差距较远。接着让上一个模型中没有被很好学习的点的权值增大一些,上一个模型已经被很好学习的点权值减少一些,形成新的样本数据接着学习。
这个过程依次进行下去,每一次生成的子模型都是再想办法弥补上一次子模型没有被成功预测的样本点,即每个子模型都是在想办法推动(Boosting)。
代码示例:
1 | from sklearn.tree import DecisionTreeClassifier |
注意Boosting方法不像Bagging有OOB了,需要使用Train-Test-Spilt方式。
另一个常见的Boosting方法叫做Gradient Boosting.
其思想如下:
- 训练一个模型m1,产生错误e1
- 针对e1训练第二个模型m2,产生错误e2
- 针对e2训练第三个模型m3,产生错误e3
- 最终预测结果是:m1+m2+m3+…
代码示例:
1 | from sklearn.ensemble import GradientBoostingClassifier |
同理如果使用Boosting 解决回归问题,可以采用下面模块:
1 | from sklearn.ensemble import AdaBoostRegressor |
Stacking
另外一种集成学习的思路叫做Stacking. 如下图所示:使用三个算法分别求出对于数据而言的预测结果3.1、2.7、2.9,但是不直接使用这三个结果综合,而是将其作为输入在添加一层算法训练一个新的模型,用这个新的模型预测结果作为输出,这种方式就叫做Stacking.
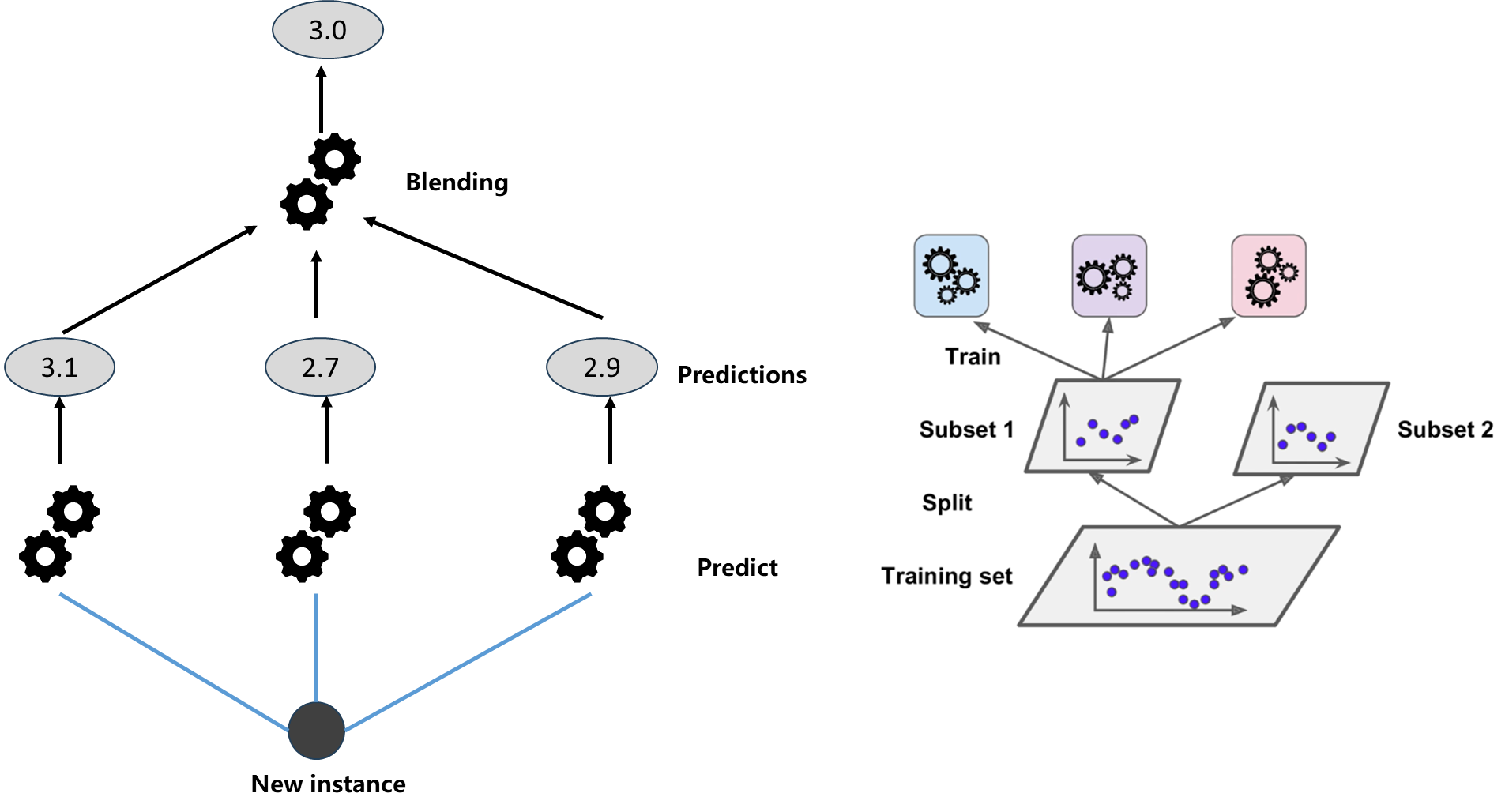
如何训练呢?如上面右图,把训练数据分成两份Subset1、Subset2,其中第一份用来训练 那三个模型,第二份用来训练最终的新模型。
XGBoost
XGBoost,全称是 Extreme Gradient Boosting(极端梯度提升),也是属于“集成学习(Boosting)”方法。从名字上看就是上面说的Gradient Boosting的极端版本。
它也是训练出一系列小的决策树,每一棵树都在前一棵树的基础上纠正错误。这样一棵棵地叠加,最终形成一个强大的预测模型。训练时,XGBoost 会先建立一个简单模型,计算预测值与真实值的误差(梯度),然后根据误差方向让下一棵树去学习“还没学好的部分”,不断迭代优化。最终模型的输出就是所有树的加权和。
它之所以比普通的梯度提升树(GBDT)更“极端”,是因为做了大量改进,比如:它在优化时不仅用了一阶导(误差方向),还用二阶导(曲率信息),使得收敛更快、更准确; 它还引入了正则化项来防止过拟合,并支持并行计算、缓存优化和稀疏特征处理,训练效率非常高。
XGBoost 的官方网址:https://xgboost.ai/